
原文来自 k6 的开发者博客,我认为文章中 进行测试的思路和最终的结果都有很高的参考价值,特意花了三天的时间翻译。长文警告。
前言
距离我们第一次发布非常受欢迎的比较和基准测试文章已经快三年了, 我们认为有必要进行更新,因为在过去几年中一些工具发生了很大变化。 对于本次更新,我们决定将所有内容都放在一篇长文中————使其更像是那些试图选择工具的人的指南。
首先,免责声明:我,作者,试图保持公正,但鉴于我参与开发了评测中的一个工具(k6),我一定会对那个工具有一些偏坦。 你大可随意查看字里行间,并对我写的关于 k6 的任何积极内容持怀疑态度。
关于评测
我们查看的工具列表没有太大变化。我们在评测中忽略了 The Grinder, 因为它尽管是我们喜欢的一个不错的工具,但似乎已不再被积极开发,安装起来更加麻烦(它需要旧的 Java 版本),而且似乎也没有很多人在用。 一位开发 k6 的同事建议我们添加一个使用 Rust 构建的工具 Drill,并认为它似乎是一个不错的选择,因此我们将其增加到评测中。 以下是待测工具的完整列表,以及我们测试的版本:
- Apachebench 2.3
- Artillery 1.6.0
- Drill 0.5.0 (new)
- Gatling 3.3.1
- Hey 0.1.2
- Jmeter 5.2.1
- k6 0.26.0
- Locust 0.13.5
- Siege 4.0.4
- Tsung 1.7.0
- Vegeta 12.7.0
- Wrk 4.1.0
那么我们当时测试了什么?
基本上,评测围绕两方面展开:
- 工具性能:该工具在负载生成方面的效率如何,其测量结果的准确性如何?
- 用户交互:对于像我这样的开发者来说,这个工具使用起来有多容易和方便?
自动化负载测试越来越成为测试开发人员关注的焦点,虽然没有时间将每个工具正确集成到 CI 测试套件中, 但作者试图弄清楚一个工具是否适合自动化:通过下载、安装、从命令行或脚本执行每个工具进行测试。
该评测既包含工具性能等硬性数据,也包含作者对工具各个方面或行为的许多非常主观的意见。
都弄清楚了?我们开始动手吧!这篇文章的其余部分以第一人称的形式写成,希望这样更吸引读者(或者至少当你不同意某方面时,你会知道该怪谁)。
历史和现状
工具概述
这是一个表格,其中包含有关评测中工具的一些基本信息。
| 工具名 | 开发者 | License | 实现语言 | 支持脚本? | 支持多线程? | 支持分布式负载生成? | 网站 | 源代码 |
|---|---|---|---|---|---|---|---|---|
| Apachebench 2.3 | Apache foundation | Apache 2.0 | C | No | No | No | httpd.apache.org | Link |
| Artillery 1.6.0 | Shoreditch Ops LTD | MPL2 | NodeJS | Yes: JS | No | No (Premium) | artillery.io | Link |
| Drill 0.5.0 (new) | Ferran Basora | GPL3 | Rust | No | Yes | No | github.com/fcsonline | Link |
| Gatling 3.3.1 | Gatling Corp | Apache 2.0 | Scala | Yes: Scala | Yes | No (Premium) | gatling.io | Link |
| Hey 0.1.2 | Jaana B Dogan | Apache 2.0 | Go | No | Yes | No | github.com/rakyll | Link |
| Jmeter 5.2.1 | Apache foundation | Apache 2.0 | Java | Limited (XML) | Yes | Yes | jmeter.apache.org | Link |
| k6 0.26.0 | Load Impact | AGPL3 | Go | Yes: JS | Yes | No (Premium) | k6.io | Link |
| Locust 0.13.5 | Jonathan Heyman | MIT | Python | Yes: Python | No | Yes | locust.io | Link |
| Siege 4.0.4 | Jeff Fulmer | GPL3 | C | No | Yes | No | joedog.org | Link |
| Tsung 1.7.0 | Nicolas Niclausse | GPL2 | Erlang | Limited (XML) | Yes | Yes | erland-projects.org | Link |
| Vegeta 12.7.0 | Tomás Senart | MIT | Go | No | Yes | Limited | tsenart@github | Link |
| Wrk 4.1.0 | Will Glozer | Apache 2.0 modified | C | Yes: Lua | Yes | No | wg@github | Link |
开发状况
好的,那么今天,即 2020 年初,哪些工具正在积极开发中?
我查看了不同工具的软件存储库,并计算了自 2017 年底我进行上一次工具评测以来的 commits 和 releases。 Apachebench 没有自己的存储库,但它是 Apache httpd 的一部分,所以我在这里跳过了它,再说了,Apachebench 已经不再开发了。
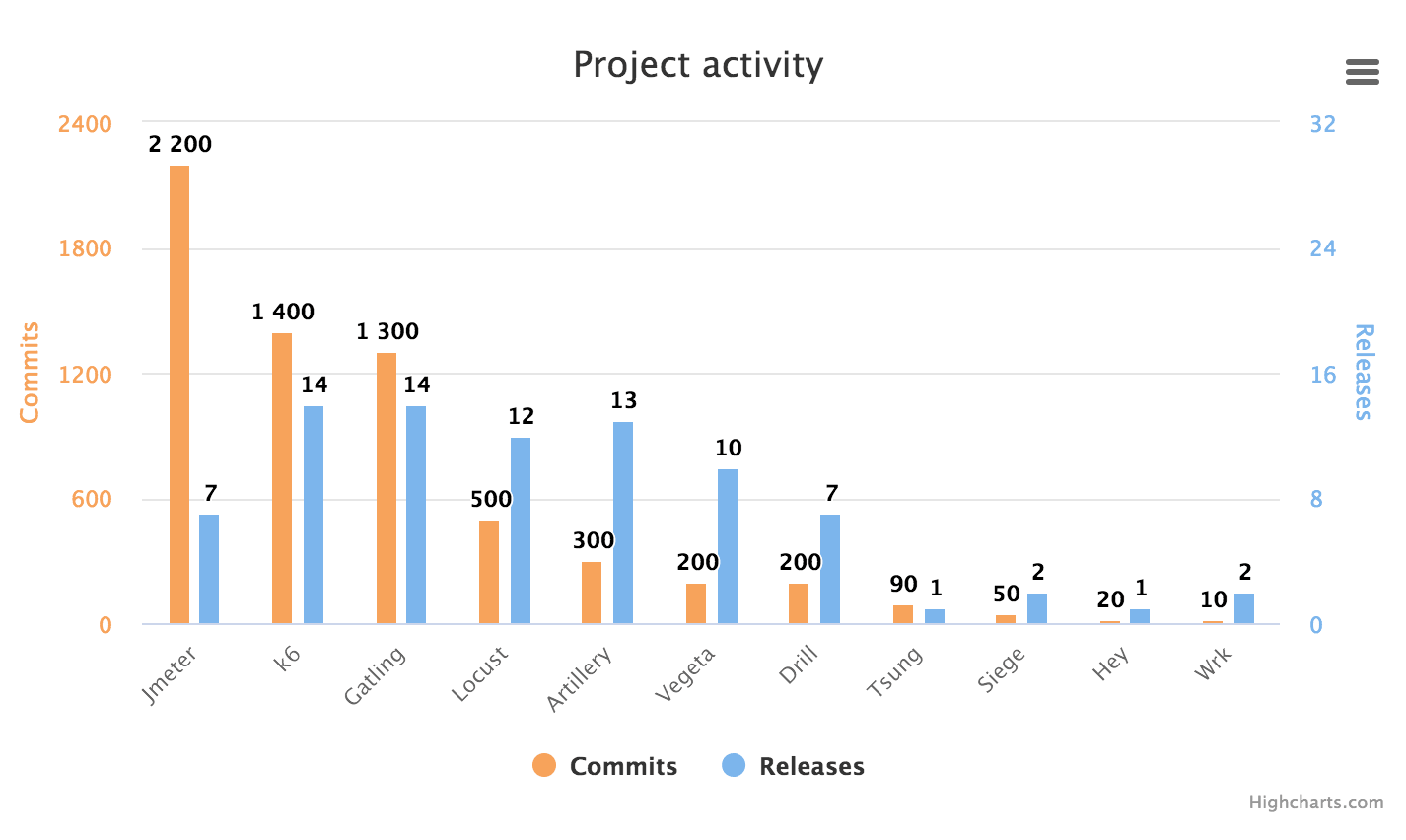
很高兴看到其中几个项目似乎进展迅速!Jmeter 也许应当更频繁地发布 releases?Locust 似乎在过去的一年里加快了更新,因为它在 2018 年只有 100 个 commits 和一个 releases,但在 2019 年它有 300 个 commits 和 10 个 releases。从提交的数量来看,Gatling、Jmeter 和 k6 似乎进展非常快。
看着 Artillery 给我的感觉是开源版本比高级版本受到的关注要少得多。阅读 Artillery Pro 的 Changelog (Artillery 开源版本似乎没有 Changelog)可知,Artillery Pro 在过去两年中增加了很多新功能,但是在查看开源 Artillery 的 Github 存储库中的 commits 消息时,我看到的大多是偶尔的 bug 修复。
Apachebench
这个老家伙是作为 Apache httpd 网络服务器工具套件的一部分开发的。它自 90 年代后期就已经存在,显然是 Zeus Technology 开发的类似工具的一个分支,用于测试 Zeus Web 服务器(Apache 和 Microsoft 的 Web 服务器的老竞争对手)。这些年来,Apachebench 并没有太多开发活动,但由于所有安装 Apache httpd 工具套件的人都可以使用它, 因此它非常易于访问,并且很可能被许多人用来快速运行针对新安装的 HTTP 服务器的性能测试。它也可能用于相当多的自动化测试套件中。
Artillery
伦敦的 Shoreditch Ops LTD 创建了 Artillery。这些人有点匿名,但我似乎记得他们是在 Artillery 流行前后转向负载测试的初创公司。 当然,我也记得其他从未发生过的事情,所以谁知道呢。无论如何,该项目似乎是在 2015 年的某个时候开始的,并且曾被命名为“Minigun”。
Artillery 是用 Javascript 编写的,并使用 NodeJS 作为其引擎。
Drill
Drill 是这些工具中最新的一个。它出现在 2018 年,是唯一用 Rust 编写的工具。显然,作者————Ferran Basora————写这个项目是为了学习 Rust。
Gatling
Gatling 于 2012 年由法国巴黎的一群前顾问首次发布,他们希望构建一个更适合测试自动化的负载测试工具。2015 年 Gatling Corp 成立,次年 Gatling Corp 发布了高级 SaaS 产品“Gatling Frontline”。在他们的网站上,他们说他们迄今为止已经达成了超过 300 万次下载————我假设这是 OSS 的下载版本。
Gatling 是用 Scala 编写的,这当然有点奇怪,但无论如何它似乎工作得很好。
Hey
Hey 曾经被命名为 Boom,在一个同名的 Python 负载测试工具出现之后,作者显然厌倦了命名造成的混乱, 所以改了名字。新名字一直让我想起“马料”,所以我还是一头雾水,但这个工具本身还不错。 它是用出色的 Go 语言编写的,并且在功能方面非常接近 Apachebench。作者表示,她编写该工具的一大目的就是替换 Apachebench。
Jmeter
这是这些工具中的老前辈。它也来自 Apache 软件基金会,是一个大型的 Java 应用程序,具有大量功能,而且仍在积极开发中。在过去的两年里,它的代码库提交量超过了评测中的任何其他工具。我怀疑 Jmeter 正在慢慢失去市场份额给新工具,比如 Gatling,但考虑到它已经存在了多长时间以及它仍然有多少动力,可以肯定它仍会称霸很久。 Jmeter 有很多集成、附加组件,以及基于它构建的整个 SaaS 服务(如 Blazemeter),而且人们花了很长时间学习如何使用它,它会在将来的很多年里继续变得强大。
k6
一个超级棒的工具!嗯,好吧,就像我之前写的那样,我在这里有些偏心。但客观事实是这样的:k6 是在 2017 年发布的,所以是相当新的。 它是用 Go 编写的,而我刚刚意识到的一件有趣的事情是,我们在 Go 和 C 之间建立了联系————评论中的三个工具是用 C 编写的,三个是用 Go 编写的。 我最喜欢的两种语言————是巧合还是模式?!
k6 最初是由 Load Impact(一种 SaaS 负载测试服务)构建并维护的。Load Impact 有几个人在 k6 上全职工作,加上社区贡献,这意味着开发非常活跃。鲜为人知的是为什么这个工具被称为“k6”,那么我很高兴能在这里透露:在一场以僵局告终的冗长的内部名称争夺战之后,我们有了一个大多数人讨厌的以“k”开头的 7 个字母的名称, 因此我们将其缩短为“k6”,这似乎解决了问题。你一定会喜欢第一世界问题!
译者注:“第一世界问题”(first-world problems)是“第一世界国家问题”的非正式表述,指的是微不足道的挫折或琐碎的烦心事, 和发展中国家所面临的严重问题形成鲜明对比。
Locust
Locust 是一个非常流行的负载测试工具,根据 releases 历史来看,至少从 2011 年起就已经存在。它的实现语言是 Python————就像是编程语言世界中的一只可爱的小狗————每个人都喜欢它!这种热爱使 Python 变得强大,也使 Locust 变得非常流行,因为实际上没有任何其他基于 Python 的靠谱的负载测试工具(而且 Locust 也支持用 Python 编写脚本!)
Locust 是由一群自己需要该工具的瑞典人创造的。它仍然由主要作者 Jonathan Heyman 维护,但现在也存在许多外部贡献者。与 Artillery、Gatling 和 k6 等不同, 没有商业企业主导 Locust 的开发————它(据我所知)是真正的社区驱动。Locust 的开发状态一直在非常活跃和不太活跃之间交替————我猜这主要取决于 Jonathan 的参与程度。 在 2018 年的平静之后,该项目在过去 18 个月左右的时间里已经产生了相当多的 commits 和 releases。
Siege
Siege 也已经存在了很长一段时间————从 2000 年初的某个时候开始。我不确定它的使用有多广泛,但它在网上很多地方被引用。 它由 Jeff Fulmer 编写,至今仍由他维护。开发仍在进行中,但各版本之间可能会间隔很长时间。
Tsung
我们唯一的 Erlang 选手!Tsung 由 Nicolas Niclausse 编写,基于一个名为 IDX-Tsunami 的老工具。 它自己也很老————出现于世纪初。同 Siege 一样,它仍然在开发中,但开发速度如蜗牛一般。
Vegeta
Vegeta 显然是某个漫画中的超级英雄之类的。该死的,现在人们会猜到我多大了。但是,真的,所有这些负载测试软件的听起来很激进的名称不是很愚蠢吗?
比如用 vegeta attack ... 开始负载测试。也不要让我开始吐槽“Artillery”、“Siege”、“Gatling”等等。
我们是要给毛头小孩耍帅吗?“Locust”至少要好一点(尽管它一直在做的“hatching”和“swarming”相当俗气)
译者注:Vegeta 是日本漫画《龙珠》系列中的主要角色,是战斗民族赛亚人的王子,拥有高傲的自尊心;“Artillery”、“Siege”、“Gatling”单词原意分别为 “炮兵”、“围攻”和“加特林”;“Locust”意为“蝗虫”,“hatching”和“swarming”单词原意分别为“孵卵”、“蜂拥”,在 Locust 中分别指生成并发用户的过程和 大流量测试服务器的过程。可见,这些名字都在暗示测试工具的高性能、大流量的特点,而作为“老年人”的作者对此很不感冒。
啊,我好像跑题了。清醒清醒!好的,我们回到正题了。Vegeta 似乎自 2014 年以来就已经存在,它也是用 Go 编写的,而且看起来很受欢迎(Github 上几乎有 14k 颗星!作为参考,非常受欢迎的 Locust 只有大约 12k 颗星)。Vegeta 的作者是 Tomás Senart,开发似乎相当活跃。
Wrk
Wrk 由 Will Glozer 用 C 语言编写。它自 2012 年以来一直存在,因此并不是什么新的工具,但我一直将它用作性能参考点,因为它速度快/效率高得离谱, 而且总体上看起来像是一款非常可靠的软件。它实际上在 Github 上也有超过 23k 颗星,因此它可能拥有相当大的用户群,尽管它比许多其他工具更难获取(你需要手动编译它)。 不幸的是,Wrk 的开发并不那么活跃,很少见到版本更新。
我认为应该有人为 Wrk 设计一个 Logo。它值得一个。
用户交互性评测
我是一名开发人员,我通常不喜欢点击式应用程序。我想使用命令行。我也喜欢通过脚本来自动化开发。我很不耐烦,想把事情做好。 我有点老了,这意味着我经常对新技术有点不信任,更喜欢经过实战验证的东西。你可能跟我不一样, 所以让我试着解释清楚我能接受什么,不能接受什么。然后你可能会从阅读我对工具的想法中得到一些启发。
我所做的是在命令行上手动运行所有工具,并将解释结果打印到标准输出或保存到文件中。然后我创建了脚本文件来提取和整理结果。
使用这些工具让我对每个工具在我的特定用例下的优缺点有了一些了解。我想我正在寻找的东西与你在设置自动负载测试时寻找的东西相似,但我可能不会考虑所有方面,因为我还没有真正将每个工具集成到一些 CI 测试套件中(这可能是下一篇要写的)————一个免责声明。
另外,请注意,工具的性能已经影响了用户交互性评测————如果我觉得很难产生我想要的流量,或者我不能相信工具的测量精度,那将在用户交互性评测中有所反映。 但是,如果你想了解有关性能的详细信息,则必须向下滚动到“性能评测”章节。
- RPS,你将在这篇博客文章中看到大量使用的术语 RPS。该首字母缩写词代表“每秒请求数”(Requests Per Second),用于衡量负载测试工具产生的流量;
- VU,这是另一个经常使用的术语。它是负载测试中“虚拟用户”(Virtual Users)的缩写。虚拟用户用于模拟人/浏览器。在负载测试中,VU 通常是指独立发出 HTTP 请求的并发线程/上下文,允许你在负载测试中同时模拟多个用户;
- 可编写脚本的工具 VS 不可编写脚本的工具,我决定为支持脚本的工具和不支持脚本的工具分开列出我最喜欢的列表。这样做的原因是,你是否需要编写脚本很大程度上取决于你的用例,并且有几个非常好的工具不支持编写脚本。
可编写脚本的工具和不可编写脚本的工具有什么区别? 可编写脚本的工具支持你用已有的脚本语言————例如 Python、Javascript、Scala 或 Lua 编写测试用例。这意味着你能在设计测试时获得最大的灵活性和最多的功能————你可以使用高级逻辑来确定测试中发生的情况,你可以引入 git 以获得额外的功能,你通常可以将代码拆分为多个文件等。它是,真的,靠谱的“开发者方案”。 另一方面,不可编写脚本的工具通常更容易上手,因为它们不需要你学习任何特定的脚本 API。它们往往也比可编写脚本的工具消耗更少的资源,因为它们不需要脚本语言运行时和脚本线程的执行上下文。因此它们更快并且消耗更少的内存(通常,并非在所有情况下都是如此)。不利的一面是它们能做的事情更加有限。
好的,让我们进入主观的工具评测!
顶级非脚本工具
以下是我最喜欢的非脚本化工具,按字母顺序排列。
Hey
$ .\hey_windows_amd64.exe -c 100 -n 10000 http://localhost:8080/hello
Summary:
Total: 0.3523 secs
Slowest: 0.1579 secs
Fastest: 0.0001 secs
Average: 0.0034 secs
Requests/sec: 28386.9781
Total data: 70000 bytes
Size/request: 7 bytes
Response time histogram:
0.000 [1] |
0.016 [9796] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
0.032 [103] |
0.047 [0] |
0.063 [0] |
0.079 [0] |
0.095 [0] |
0.111 [0] |
0.126 [52] |
0.142 [38] |
0.158 [10] |
Latency distribution:
10% in 0.0007 secs
25% in 0.0011 secs
50% in 0.0016 secs
75% in 0.0024 secs
90% in 0.0039 secs
95% in 0.0049 secs
99% in 0.1208 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0001 secs, 0.0001 secs, 0.1579 secs
DNS-lookup: 0.0001 secs, 0.0000 secs, 0.0097 secs
req write: 0.0000 secs, 0.0000 secs, 0.0159 secs
resp wait: 0.0030 secs, 0.0000 secs, 0.1473 secs
resp read: 0.0002 secs, 0.0000 secs, 0.0140 secs
Status code distribution:
[200] 10000 responses
Hey 是一个简单的工具,用 Go 编写,具有良好的性能和运行简单静态 URL 测试所需的最常见功能。 它不支持任何类型的脚本,但可以作为 Apachebench 或 Wrk 等工具的良好替代品,用于简单的负载测试。 Hey 支持 HTTP/2————Wrk 和 Apachebench 都不支持————虽然我不认为 HTTP/2 支持在 2017 年有什么大不了的,但今天我们可以发现 HTTP/2 的渗透率比当时高很多, 所以我可以说,在今天它更是 Hey 的优势。
使用 Hey 而不是 Apachebench 的另一个潜在原因是 Hey 是多线程的,而 Apachebench 不是。Apachebench 非常快,因此通常你不需要多个 CPU 内核就能生成足够的流量, 但如果你真的需要,那么你会更乐意使用 Hey,因为它的负载生成能力将与你的机器上的 CPU 内核的数量呈线性关系。
Hey 有速率限制功能,可用于运行固定 rps 测试。
总的来说,Hey 很简单,但它做得很好。它很稳定,是评测中性能较高的工具之一,并且具有非常好的终端输出,包括响应时间直方图、百分位数等。 它还具有速率限制功能,这是许多工具所缺乏的。
Vegeta
$ echo "GET http://localhost:6060/" | vegeta attack -duration=10s | vegeta report
Requests [total, rate, throughput] 1200, 120.00, 65.87
Duration [total, attack, wait] 10.094965987s, 9.949883921s, 145.082066ms
Latencies [min, mean, 50, 95, 99, max] 90.438129ms, 113.172398ms, 108.272568ms, 140.18235ms, 247.771566ms, 264.815246ms
Bytes In [total, mean] 3714690, 3095.57
Bytes Out [total, mean] 0, 0.00
Success [ratio] 55.42%
Status Codes [code:count] 0:535 200:665
Error Set:
Get http://localhost:6060: dial tcp 127.0.0.1:6060: connection refused
Get http://localhost:6060: read tcp 127.0.0.1:6060: connection reset by peer
Get http://localhost:6060: dial tcp 127.0.0.1:6060: connection reset by peer
Get http://localhost:6060: write tcp 127.0.0.1:6060: broken pipe
Get http://localhost:6060: net/http: transport closed before response was received
Get http://localhost:6060: http: can't write HTTP request on broken connection
Vegeta 有很多很酷的特性,比如它的默认模式是以恒定速率发送请求,它会通过调整并发用户数来保持这个速率。 这对于回归/自动化测试非常有用,在这些测试中,你经常希望运行尽可能相同的测试,因为这将使新提交代码中的问题通过测试结果的偏离表现出来。
Vegeta 是用 Go(yay) 编写的,性能非常好,支持 HTTP/2,有多种输出格式和灵活的报告,并且可以生成响应时间图。
如果你查看上面的运行时终端输出,你会发现 Vegeta 很明显被设计为在命令行上运行;它从标准输入读取要生成的 HTTP 请求列表,并将结果以二进制格式发送到标准输出, 然后你可以把它重定向到文件中,或将它直接通过管道传输到另一个 Vegeta 进程以从数据生成报告。
这种设计提供了很大的灵活性并支持新的使用方法,例如在不同主机上执行 Vegeta 的基本负载生成, 然后从每个 Vegeta slave 收集二进制输出并将其全部传输到一个 Vegeta 进程中,由该进程生成一个报告。 你还可以动态生成 Vegeta 需要压测的 URL 列表,这意味着你可以让一个软件执行复杂的逻辑来生成这个 URL 列表(然而该程序无法访问测试的结果,所以我怀疑这样的设置会有多大用处)。
稍微不利的一面是,如果你使用过其他负载测试工具,它的命令行交互可能不是你所习惯的,而且如果你只是想针对单个 URL 运行快速的命令行测试,它也不是最简单的。
总的来说,Vegeta 是一个非常强大的工具,它迎合了那些想要一个工具来测试简单的静态 URL(可能是 API 端点)但又想要更多功能的,或者想要组装自己的负载测试解决方案并需要可以以不同方式使用的灵活负载生成器组件的人。如果你想创建自己的负载测试工具,Vegeta 甚至可以用作 Golang 库/包。
最大的缺陷(当我是用户时)是缺乏可编程脚本,这使它显得不那么以开发人员为中心。
我肯定会使用 Vegeta 进行简单的自动化测试。
Wrk
$ wrk -t 4 -c 100 -d 3s --latency http://localhost:8080/hello
Running 3s test @ http://localhost:8080/hello
4 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.87ms 1.37ms 35.78ms 89.73%
Req/Sec 11.38k 1.09k 17.67k 86.67%
Latency Distribution
50% 1.63ms
75% 1.95ms
90% 2.80ms
99% 6.43ms
136185 requests in 3.01s, 16.75MB read
Requests/sec: 45233.10
Transfer/sec: 5.56MB
Wrk 可能有点过时了,并且这些年并没有增加很多新功能,但它就是这样一个极其可靠的程序。它总是表现得像你期望的那样,并且在速度/效率方面远超其他所有工具。 如果你使用 Wrk,你将能够在相同的硬件上生成 5 倍于 k6 的流量。如果这听起来好像是在说 k6 很糟糕,那你错了,因为 k6 并不慢,只是 Wrk 实在是太快了。 与其他工具相比,Wrk 比 Gatling 快 10 倍,比 Locust 快 15-20 倍,比 Artillery 快 100 倍以上。
这种比较有点不公平,因为一些工具允许让它们的 VU 线程运行比 Wrk 允许的更复杂的脚本,但快就是快。你也许会认为 Wrk 根本不支持脚本,但它实际上允许你在 VU 线程中执行 Lua 代码,理论上,你可以创建相当复杂的测试代码。然而,在实践中,Wrk 脚本 API 是基于回调的,根本不适合编写复杂的测试逻辑。而它带上脚本照样非常快。 这次我在测试 Wrk 时没有执行 Lua 代码————我改用了单 URL 测试模式,但之前的测试表明,在执行 Lua 代码时 Wrk 的性能受到的影响很小。
然而,快速高效和精确测量就是 Wrk 所能做的一切。它没有 HTTP/2 支持,没有固定的请求速率模式,没有多种输出选项,没有在 CI 设置中手动标识“通过”/“失败”的方法等。 简而言之,它的功能非常贫瘠。
Wrk 包含在顶级不可编写脚本的工具列表中,因为如果你的唯一目标是针对站点生成巨量的简单流量,那么没有任何工具可以更有效地做到这一点。 它还将为你保证响应时间的准确测量,而许多其他工具在被迫产生巨量流量时不能保证这一点。
顶级脚本工具
对我来说,这是最有趣的类别,因为在这里你能找到支持编程,可以以你想要的任何奇怪方式运行的工具! 或者,用一种更无聊的方式来说,这里有一些工具可以让你将测试用例编写为纯代码,就像在开发其他软件一样。
请注意,我仍按字母顺序列出了顶级工具————我不会对它们进行排名,因为排名很愚蠢。 阅读信息,然后用你脖子上的肿块来确定你应该使用哪种工具。
Gatling
Gatling 实际上并不是我的最爱,因为它是一个 Java 应用程序,而我不喜欢 Java 应用程序。对于整天在 Java 环境中工作的人来说,Java 应用程序可能很容易使用,但对于其他人来说,它们绝对不是用户友好的。每当大多数其他语言编写的应用程序出现故障时,你都会收到一条错误消息,通常可以帮助你找出问题所在。 如果 Java 应用程序失败,你将获得 1,000 行堆栈信息和重复的通用错误消息,这些消息绝对是零帮助的。此外,运行 Java 应用程序通常需要手动调整 JVM 运行时参数。 也许 Java 非常适合大型企业后端软件,但不适用于负载测试工具之类的命令行应用程序,因此在我这里,作为 Java 应用程序是一个明显的缺点。
如果你查看上面的屏幕截图,你会注意到你必须在“JAVA_OPTS”环境变量中向测试添加参数,然后从 Gatling Scala 脚本中读取该参数。 没有任何命令行参数可以让 Gatling 改变并发/VU、持续时间或类似的属性,这必须由 Scala 代码给出。当你仅以自动化方式运行某些东西时,这种处理方式很好, 但如果你想在命令行上运行几个手动测试,则有点痛苦。
尽管以 Java 为中心,我不得不说 Gatling 是一个非常好的负载测试工具。它的性能不是很好,但对于大多数人来说可能已经足够了。它有一个不错的基于 Scala 的脚本环境。 同样,Scala 不是我的菜,但如果你喜欢它,或者 Java,用 Gatling 编写测试用例应该很方便。
译者注:本文不代表译者观点,我完全不同意作者对 Java 的偏见,~(^_^)~;另外,Scala is AWESOME!!!
下面是一个非常简单的 Gatling 脚本的样子:
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class GatlingSimulation extends Simulation {
val vus = Integer.getInteger("vus", 20)
val duration = Integer.getInteger("duration", 10)
val scn = scenario("Scenario Name") // A scenario is a chain of requests and pauses
.during (duration) {
exec(http("request_1").get("http://192.168.0.121:8080/"))
}
setUp(scn.inject(atOnceUsers(vus)))
}
脚本 API 似乎很有能力,它可以根据用户自定义的条件生成“通过”/“失败”结果。
我不喜欢在启动 Gatling 时默认显示的基于文本的菜单系统。幸运的是,可以通过使用正确的命令行参数来跳过它。如果你稍微深入研究一下,Gatling 很容易从命令行运行。
Gatling 的文档非常好,这对任何工具来说都是一大优势。
Gatling 有一个看起来很靠谱的脚本录制工具,虽然我自己没有尝试过,因为我更感兴趣的是用脚本模拟场景来测试单个 API 端点,而不是在网站上记录“用户操作”。 但我想许多需要模拟最终用户行为的复杂负载测试场景的人会对这个功能感到满意。
Gatling 默认将结果报告到标准输出并在测试完成后生成漂亮的 HTML 报告(使用我最喜欢的图表库————Highcharts)。 很高兴看到它最近还支持将结果输出到 Graphite/InfluxDB 和使用 Grafana 进行可视化。
总的来说,Gatling 是一个非常靠谱的工具,并且得到了积极的维护和开发。如果你还在使用 Jmeter,那么你绝对应该看看 Gatling,看看你缺少什么(提示:用户交互性!)。
k6
由于我参与了 k6 的开发,因此我喜欢该项目所做的设计抉择并不奇怪。k6 背后的想法是为现代开发人员创建一个高质量的负载测试工具,它允许你将测试编写为纯代码,具有简单且一致的命令行交互,具有有用的结果输出选项,并且具有足够好的性能. 我认为所有这些目标都已基本实现,这使得 k6 成为负载测试工具中非常引人注目的选择。特别是对于像我这样的开发人员。
k6 可以用纯 Javascript 编写脚本,并且拥有我认为是我测试过的所有工具中最好的脚本 API。该 API 可以轻松执行常见操作、测试请求是否按预期运行,以及控制自动化测试的“通过”/“失败”行为。这是一个非常简单的 k6 脚本的样子:
import http from 'k6/http';
import { check } from 'k6';
export default function () {
const res = http.get('http://192.168.0.121:8080/');
check(res, {
'is status 200': (r) => r.status === 200,
});
}
上面的脚本将使每个 VU 生成一个 HTTP 事务,然后检查响应代码是否为 200。这样的检查状态会打印在标准输出上, 你还可以设置阈值以使整个测试在足够大的百分比检查失败后显示为整体失败。k6 脚本 API 使编写自动化性能测试的体验非常好。
k6 命令行界面简单、直观且一致————感觉很现代。k6 是本次评测中速度较快的工具之一,它支持所有基本协议(HTTP 1/2/Websocket),具有多种输出选项(文本、JSON、InfluxDB、StatsD、Datadog、Kafka)。从浏览器录制流量非常容易,因为 k6 可以将 HAR 文件转换为 k6 脚本,并且主流浏览器可以录制会话并将其保存为 HAR 文件。 此外,还有一些选项可以将 Postman collections 转换为 k6 脚本代码。哦,是的,文档总体上是一流的(尽管我刚刚和一个从事文档工作的人交谈,他对他们今天的状态不满意,我认为这很好。当产品开发人员满意时,产品就会停滞不前)。
那么 k6 缺少什么?好吧,分布式负载生成不包括在内,所以如果你想运行真正大规模的测试,你必须购买高级 SaaS 版本(具有分布式负载生成)。 另一方面,它的性能意味着无论如何你都不太可能耗尽单个物理机器上的负载生成能力。 k6 不会附带任何类型的 Web UI,如果你喜欢这样的 UI 的话可能会失望,反正我不喜欢。
大家可能期望但 k6 没有的一样特性是 NodeJS 兼容性。许多(甚至可能是大多数?)NodeJS 库不能在 k6 脚本中使用。如果你需要使用 NodeJS 库,Artillery 可能是你唯一靠谱的选择(哦不!)。
我唯一不喜欢 k6 的地方就是我必须用 Javascript 编写测试脚本!JS 不是我最喜欢的语言,就我个人而言,我更喜欢使用 Python 或 Lua————后者是 Load Impact 多年来一直用来编写负载测试脚本的脚本语言,并且非常节省资源。但就市场渗透率而言,Lua 是果蝇,而 JS 是大象,所以选择 JS 而不是 Lua 是明智的。老实说,只要脚本不是用 XML(或 Java)编写的,我就很高兴。
如前所述,k6 的开源版本正在非常积极地开发,并且一直在添加新功能。请查看发行说明/变更日志,顺便说一句,这是我见过的写得最好的(感谢维护者@na——他是编写这些东西的专家)。
k6 的内置帮助也值得一提,这比这篇评测中的任何其他工具都要好得多。它具有 docker 风格的多层次 k6 help 命令,你可以在其中提供参数以显示特定命令的帮助。
例如 k6 help run 将为你提供详尽的帮助文本,展示如何使用 run 命令。
并不是说我有偏见,但是我认为,当你考虑开发人员的整个体验时,k6 领先于其他工具。 有更快的工具,但这些更快的工具未必支持复杂的脚本。有些工具支持更多协议,但 k6 支持最重要的协议。有带更多输出选项的工具,但 k6 毕竟比大多数工具都多。 在几乎每个指标中,k6 都是平均水平或更好的。在某些指标(文档、脚本 API、命令行交互)中,它非常出色。
Locust
Locust 的脚本编写体验非常好。Locust 脚本 API 非常好,虽然只有基础功能,缺少其他 API 所具有的一些有用的东西,例如自定义“通过”/“失败”结果。
不过,Locust 脚本的独特之处在于————你可以使用 Python 编写脚本!你的情况可能会有所不同,但如果我可以选择任何脚本语言来进行负载测试,我可能会选择 Python。以下是 Locust 脚本的实例:
from locust import TaskSet, task, constant
from locust.contrib.fasthttp import FastHttpLocust
class UserBehavior(TaskSet):
@task
def bench_task(self):
while True:
self.client.get("/")
class WebsiteUser(FastHttpLocust):
task_set = UserBehavior
wait_time = constant(0)
不错吧?可以说比 k6 脚本看起来更好,但 API 确实缺少一些东西,比如对标识“通过”/“失败”结果的内置支持(Blazemeter 有一篇关于如何为 Locust 实现自己的断言的文章,其中涉及生成 Python 异常并获得堆栈跟踪————听起来有点过于崎岖了)。此外,新的 FastHttpLocust 类(在下面阅读更多内容)似乎在功能上有点受限(例如,不确定是否支持 HTTP/2?)
Locust 有一个很好的 Web UI,可以显示测试的实时状态,并且支持停止测试或重置统计信息的控制选项。此外,它还内置了易于使用的分布式负载生成。
使用 Locust 的分布式负载测试只需要在主进程启动时加上 --master 参数,然后使用 --slave 参数启动多个工作进程并将它们指向主进程所在的地址。
Locust 的 Web UI 整洁且实用。即使我在其他地方写了我不喜欢 Web UI,但有时当你需要控制许多负载生成器并监控它们的状态时,UI 会非常好用。
Python 实际上是 Locust 的最大优点和最大缺点。它的缺点是 Locust 是用 Python 编写的。Python 代码很慢,这会影响 Locust 生成流量和提供精确测量的能力。
我第一次对 Locust 进行基准测试是在 2017 年,当时的表现非常糟糕。与我测试过的任何其他工具相比,Locust 生成一个 HTTP 请求需要使用更多的 CPU 时间。 更糟糕的是,Locust 是单线程的,所以如果你不运行多个 Locust 进程,Locust 只能使用一个 CPU 内核,根本无法产生太多流量。幸运的是,即使在那时,Locust 也支持分布式负载生成,这使得它在单个物理机器可以产生多少流量方面从表现最差变成第二差。当时关于 Locust 的另一个负面评价是,它往往会给测量的响应时间增加大量延迟,使测量结果变得非常不靠谱。
很酷的是,从那时起,Locust 开发人员进行了一些更改,并真正加快了 Locust。这是独一无二的,因为在过去两年中,所有其他工具的性能都保持不变或倒退。 Locust 引入了一个名为 FastHttpLocust 的新 Python 类/库,它比旧的 HttpLocust 类(基于 Requests 库构建)快得多。在我现在的测试中,我发现简单请求的生成能力提高了 4-5 倍,这也与 Locust 作者在文档中描述的一致。这意味着具有 4-8 个 CPU 内核的典型现代服务器应该能够在分布式模式下用 Locust 生成 5-10k RPS。 注意由于 Locust 仍然是单线程的,因此通常仍然需要分布式执行。在基准测试中,我还注意到,当你在分布式模式下运行 Locust 时,随着工作量的增加, Locust 的测量精度的下降会更优雅。
这些改进带来的好处是,现在很多人可能会发现,在运行 Locust 时,单个物理服务器就足够支撑他们的负载测试。他们将能够使大多数内部系统饱和,甚至可能使生产环境的系统(或它们的副本)饱和。Locust 仍然是评测中性能较低的工具之一,但至少现在它的性能不再会使其变得不堪一用。
就个人而言,我对 Locust 有点纠结。我喜欢用 Python 编写脚本(并使用一百万个 Python 库!)。这对我来说是迄今为止最大的卖点。我喜欢内置的分布式负载生成,但不相信它可以扩展到真正的大规模测试(我怀疑主从架构中的单个 master 将很快成为瓶颈————测试会很有趣)。我喜欢脚本 API,尽管它不支持自定义“通过”/“失败”结果,而且 FastHttpLocust 的 HTTP 功能支持似乎不完全。我喜欢内置的网络用户界面。我不喜欢它整体的低性能————可能迫使我在单个主机上分布式运行 Locust————必须配置多个 Locust 实例无疑增加了额外的复杂性(尤其是对于自动化测试)。我不太喜欢它的命令行交互。
关于在单个主机上的分布式执行————我不知道让 Locust 默认启动 master 进程,然后自己为每个检测到的 CPU 内核创建一个 slave 子进程有多难?(当然,如果用户想要控制它,一切都可以配置)让它像 Nginx 那样工作。这将带来更好的用户体验,配置过程将不那么复杂————至少当你在单个主机上运行它时。
如果不是有 k6,Locust 将是我的首选。如果你真的很喜欢 Python,你绝对应该先看看 Locust,看看它是否适合你, 看看脚本 API 是否能以简单的方式做你想做的事情,并且性能足够好。
其余工具
以下是我对其余工具的评论。
Apachebench
Apachebench 的开发不是很活跃,而且已经过时了。我将它包括在内主要是因为它很常见,是 Apache httpd 捆绑的实用程序的一部分。 Apachebench 速度很快,但是是单线程的。它不支持 HTTP/2,也没有脚本功能。 它非常适合对单个 URL 进行简单的压测。这种使用场景下的唯一竞争对手是 Hey(它是多线程的并支持 HTTP/2)。
Artillery
Artillery 是一个非常缓慢、非常消耗资源并且可能不是非常积极开发的开源负载测试工具。我猜这不是一个非常讨人喜欢的总结,但请继续阅读。
它是用 Javascript 编写的,使用 NodeJS 作为引擎。在 NodeJS 之上构建的好处是 NodeJS 兼容性:Artillery 可以在 Javascript 中编写脚本并且可以使用常规的 NodeJS 库,这是 k6 无法做到的,尽管 k6 也可以在常规 Javascript 中编写脚本。然而,作为 NodeJS 应用程序的坏处在于性能:在 2017 年的基准测试中,Artillery 被证明是仅次于 Locust 的表现第二差的应用程序。它使用了大量的 CPU 和内存,却只实现了相当不起眼的 RPS 和糟糕的测量精度。
我很遗憾地说,自 2017 年以来,情况并没有太大变化。如果偏要说的话,今天的 Artillery 似乎更慢了。
2017 年,在单个 CPU 内核上运行,Artillery 可以产生两倍于 Locust 的流量。而在今天,当这两种工具同样受限于使用单个 CPU 内核时,Artillery 只能产生 Locust 可以产生的流量的 1/3。部分原因是 Locust 的性能有所提高,但提高程度理应没有对比中这么巨大,所以我很确定 Artillery 的性能也有所下降。另一个支持该论点的对比是 Artillery vs Tsung。2017 年,Tsung 的速度是 Artillery 的 10 倍。如今,Tsung 的速度是其 30 倍。我确信 Tsung 的性能根本没有改变,这意味着 Artillery 比以前慢了很多(虽然当时也不快)。
Artillery 的性能绝对是个问题,而一个更严重的问题是开源的 Artillery 仍然没有任何类型的分布式负载生成支持,因此除非你购买高级 SaaS 产品,否则你将陷入性能非常低下的解决方案。
artillery.io 网站没讲清楚 Artillery 开源版本和 Artillery Pro 之间有什么区别,但似乎只有 Artillery Pro 的 Changelog,查看 Github repo,Artillery 开源版本的版本号是 1.6.0,而根据 Changelog,Pro 为 2.2.0。看看开源 Artillery 的 commits 消息,似乎大部分是 bug 修复, 并且在 2 年多的时间里没有太多的 commits。
Artillery 团队应该更好地写明 Artillery 开源版本和高级版本 Artillery Pro 之间的差异,并表明他们对开源产品的态度。 是不是慢慢停止维护了?看起来确实是这样。
另一件与性能相关的注意事项是,如今,只要 CPU 使用率超过 80%(单核),Artillery 就会打印“high-cpu”警告,建议不要超过该数量,以免“降低性能”。我发现如果我保持大约 80% 的 CPU 使用率以避免这些警告,Artillery 将产生更少的流量————大约是 Locust 每秒可以执行的请求数的 1/8。 如果我忽略警告消息并让 Artillery 使用一个核心的 100%,它会将 RPS 增加到 Locust 的 1/3。但代价是相当大的测量误差。
除了所有的性能问题,Artillery 也有一些好的方面。它非常适合 CI/自动化,因为它易于在命令行上使用,具有简单简洁的基于 YAML 的配置格式,用于自定义“通过”/“失败”结果的插件,以 JSON 格式输出结果等。就像前面提到的,它可以使用常规的 NodeJS 库,这些库提供了大量易于导入的功能。 但是当一个工具表现得像 Artillery 时,所有这些对我来说都无关紧要。 我会考虑使用 Artillery 的唯一情况是:我的测试用例必须依赖一些 k6 无法使用但 Artillery 可以使用的 NodeJS 库。
总的来说,仅当你已经将自己的灵魂卖给了 NodeJS(即,如果你必须使用 NodeJS 库)时才使用它。
Drill
Drill 是用 Rust 编写的。我避免使用 Rust 是因为我害怕自己可能会喜欢它,并且破坏自己和 Golang 之间的亲密关系。 但这可能不在本文的范围内。我的意思是 Rust 应该很快,所以我的假设是用 Rust 编写的负载测试工具也会很快。
然而,运行一些基准测试后,我很快就发现这个工具非常慢!也许我不应该这么快就将 Drill 包括在评测中,因为它不但很新而且还没有被广泛使用。 也许作者并不是在努力创造一个新工具?(鉴于作者声称开发 Drill 是因为他想学习 Rust)。另一方面,它确实有很多有用的功能,比如非常强大的基于 YAML 的配置文件格式、“通过”/“失败”结果的阈值等,所以对我来说,它看起来确实有一半努力。
所以,该工具似乎在简单使用(不用脚本)时相当可靠。但是当我在我的测试环境中运行它时,它会榨干四个 CPU 内核并产生令人难以置信的 180 RPS。就这还是在我进行了许多测试,使用了许多不同的参数,才能从 Drill 中挤出的最好的数字。CPU 使出了浑身解数,但是从这个工具发出的 HTTP 事务仍然非常少,我可能可以用笔和纸来响应它们。就像在每个 HTTP 请求之后都会挖一会比特币一样!将此与在同一环境中执行超过 50,000 RPS 的 Wrk(用 C 编写)进行比较,你就会明白我的意思。Drill 并不是哪种能证明“Rust 比 C 更快”的说法的工具。
如果你的应用程序性能垃圾,那么使用像 Rust 这样的编程语言有什么意义?那你不妨用 Python。不对,基于 Python 的 Locust 比这快得多。如果我的某个测试设置的目标是 200 RPS 左右,我可能会使用 Perl!或者,见鬼,甚至可能是一个 shell 脚本?
让我来试一试。看看 curl-basher。
这个 Bash 脚本实际上会同时在命令行上多次执行 curl。它甚至会计算错误数。 curl-basher 设法在我的测试环境中勉强维持了 147 RPS(我不得不说,非常稳定的 147 RPS),而 Drill 做到了 175-176 RPS,所以它只快了 20%。 这让我好奇 Drill 代码到底做了什么才能设法消耗这么多 CPU 时间。它肯定创造了新的记录————生成 HTTP 请求的最低效率记录————如果你担心全球变暖,请不要使用 Drill!
对于小流量的、短期的负载测试,Drill 才能用,或者如果房间有点冷。
Jmeter
这是 800 磅重的大猩猩。与大多数其他工具相比,Jmeter 是一个巨型野兽。它是老的,并且拥有比这篇评测中的任何其他工具都更大的功能集、更多的集成、附加组件、插件等。长期以来,它一直是开源负载测试工具的“王者”,而且很可能仍将是。
在过去,人们要么选择为 HP Loadrunner 许可证支付大量金钱、为某些 Loadrunner-wannabe 专有工具的许可证支付大量金钱,要么选择根本不支付任何费用来使用 Jmeter。好吧,也可以选择使用 Apachebench 或 OpenSTA 或其他一些被遗忘的免费解决方案,但如果你想做认真的负载测试,Jmeter 确实是唯一可用的不花钱的替代方案。
所以 Jmeter 的用户群越来越大,Jmeter 的发展也越来越好。现在,大约 15 年后,Jmeter 已经由一个大型社区积极开发维护,而且积极开发维护的时间比任何其他负载测试工具都要长,所以它拥有比任何其他工具更多的功能也就不足为奇了。
由于它最初是作为 15-20 年前旧的专有负载测试软件的替代品而构建的,因此它旨在迎合与这些应用程序相同的受众。即,它旨在供负载测试专家使用,这些专家运行复杂的、大规模的集成负载测试,这些测试需要花费很长时间才能进行计划、很长时间才能执行并且需要更长的时间来分析结果,这些测试需要大量人工工作和非常专业的负载测试领域知识。这意味着 Jmeter 从一开始就不是为自动化测试和开发人员使用而构建的,今天使用它时可以清楚地感受到这一点。它是专业测试人员的工具,不适用于开发人员。它不适合自动化测试,因为它的命令行使用很笨拙,默认结果输出选项有限,它使用大量资源并且没有真正的脚本功能,仅支持在 XML 配置中插入逻辑。
这可能就是为什么 Jmeter 正在被像 Gatling 这样的新工具抢走市场份额,它与 Jmeter 有很多共同之处,因此它为想要使用更现代工具的组织提供了一个有吸引力的升级选项————更好地支持脚本和自动化,但是希望保持他们的工具是基于 Java 的。不管怎样,Jmeter 确实比 Gatling 有一些优势。 这主要取决于生态系统的规模————我提到的所有这些集成、插件等。在性能方面,它们非常相似。Jmeter 曾经是本次评测中性能最好的工具之一,但它的性能下降了,所以现在它大约是平均水平,并且非常接近(可能略快于)Gatling。
如果你刚刚开始进行负载测试,那么今天仍选择 Jmeter 的最大原因可以是:
- 需要测试许多只有 Jmeter 支持的不同协议/应用程序,
- 或者你是一个以 Java 为中心的组织,并希望使用最常见的基于 Java 的负载测试工具,
- 或者你想要一个 GUI 负载测试工具,以使你可以在其中点来点去以执行操作。
否则的话,我认为 Gatling(在很多方面都非常接近 Jmeter)、k6 或 Locust 能为你提供更好的服务。或者,如果你不太关心可编程性/脚本(将测试编写为代码),你可以看看 Vegeta。
Siege
Siege 是一个简单的工具,类似于 Apachebench,因为它不支持脚本,主要用于当你想要重复压测单个静态 URL 时。 它相较于 Apachebench 增加的最有用特性是它能够读取 URL 列表并测试它们全部。但是,如果你不需要此功能,那么我的建议就是使用 Apachebench(或者更好的工具————Hey)。因为如果你尝试用它做任何稍微高级一点的事情,Siege 肯定会让你头疼————比如弄清楚目标站点遇到流量时的响应速度,或者产生足够的流量来减慢目标系统的速度,或者其他什么像这样的事情。实际上,仅使用正确的配置或命令行选项运行它————虽然这已经很简单了————感觉也像某种神秘的益智游戏。
Siege 在不少方面都是不可靠的。首先,它经常崩溃。其次,它卡死得更经常(主要是在程序结束时,记不清我用 kill -9 杀死它多少次了)。
如果你尝试启用 HTTP keep-alive,它有 25% 的可能会崩溃或卡死。我不明白 HTTP keep-alive 在这样一个老工具中怎么会还是实验性功能!HTTP keep-alive 本身非常古老,是 HTTP/1.1 的一部分,20 年前就已经标准化了!它现在到处都非常非常常用,并且对性能有巨大的影响。大多数 HTTP 库都支持它。
HTTP keep-alive 使连接在请求之间保持打开状态,因此可以重用连接。如果无法保持连接打开,则意味着每个 HTTP 请求都会导致新的 TCP 握手和新连接。这可能会给你带来误导性的响应时间结果(因为每个请求都涉及 TCP 握手,并且 TCP 握手很慢)并且还可能导致目标系统上的 TCP 端口饥饿。
但是,嘿,你不必启用奇怪的、新奇的、实验性的、前沿的东西,比如 HTTP keep-alive,也能让 Siege 崩溃。你只需要让它多启动一些线程,它就会很快崩溃或挂起。它使用障眼法来避免提及这个事实————它有一个新的 limit 配置参数,可以限制 -c(concurrency)命令行参数的最大值————-c 是确定 Siege 将启动多少线程的参数。limit 的值默认设置为 255,其动机是 Apache httpd 默认只能处理 255 个并发连接,因此使用更多连接会“弄得一团糟”。简直就是牛牧场里的一堆不可名状的棕色东西。碰巧在我的测试过程中,当并发用户数被设置到 3-400 范围内的某个位置时,Siege 似乎就变得不稳定。
超过 500 会让它崩溃或挂起得更加频繁。更诚实的做法是在文档中写下“抱歉,我们似乎不能创建超过 X 个线程,否则 Siege 会崩溃。正在努力解决”
Siege 的参数是由不一致的、不直观的选项拼凑而成的,有时 help 还会对你撒谎。我还无法使用 -l 选项(据说可用于指定日志文件位置),
尽管长格式的 --log=x 似乎像宣传的那样能用(这不就是 -l 的全称吗)。
Siege 现在的性能与 Locust 不相上下(当 Locust 以分布式模式运行时),这对于 C 程序来说并不是很好的成绩。Wrk 比 Siege 快 25 倍,提供几乎相同的功能,更好的测量精度并且不会崩溃。Apachebench 也快得多,Hey 也是如此。我现在似乎看不到使用 Siege 的理由。
我能想到的 Siege 的唯一真正积极的事情是实现了大多数工具所缺乏的非常聪明的东西————命令行开关(-C),它要求读取所有配置数据(加上命令行参数),然后打印出运行负载测试时将使用的完整配置。这是一个更多的工具应该有的非常好的功能。尤其是当有多种配置方式时————即命令行选项、配置文件、环境变量————要准确了解你实际使用的配置可能会很棘手。
总的来说……傻孩子,快跑呀。
Tsung
Tsung 是我们的评测中唯一一个基于 Erlang 的工具,它已经存在了一段时间。它看起来非常稳定,有很好的文档,速度相当快,并且有一些很好的特性,包括对分布式负载生成的支持和对多种不同协议的支持。
这是一个非常靠谱的工具,在我看来,它的主要缺点是类似于 Jmeter 的基于 XML 的配置,并且缺乏脚本语言支持。就像 Jmeter 一样,你实际上可以在 XML 配置中定义循环并使用 if-else 之类的东西,因此非要较真的话你确实可以编写测试脚本,但是与使用真正的编程语言(例如 JS 或 Python)相比,用户体验非常糟糕。
Tsung 仍在开发中,但进展非常缓慢。总而言之,我想说,如果你需要测试它支持的额外协议之一(如 LDAP、PostgreSQL、MySQL、XMPP/Jabber), 你可能只能在 Jmeter 和 Tsung 之间进行选择(在这两个中,我更喜欢 Tsung)。
如果你是 Erlang 粉丝,可以尝试一下。
curl-basher
嗯,怎么说呢。
性能评测和基准测试
负载测试可能很棘手,因为在负载生成的一侧遇到一些性能问题是很常见的,这意味着你正在测量系统生成流量的能力,而不是目标系统处理流量的能力。即使是经验丰富的负载测试专业人员也经常落入这个陷阱。
如果你没有足够的负载生成能力,你可能会看到负载测试无法超过一定的 RPS,或者你可能会看到响应时间测量变得完全不可靠。通常你会看到这两种情况都发生了,但你可能不知道为什么并且错误地将你看到的糟糕和不稳定的性能归咎于目标系统。然后你要么会尝试优化你已经优化的代码(因为我相信以你的水平,你的代码一定很快),要么会对一些可怜的同事大喊大叫(尽管他们可能并未参与开发这部分代码),毕竟这代码看上去像是整个测试中唯一可能存在性能问题的地方。然后同事生气,偷了你的鼠标垫来报复,这挑起了办公室里的一场战争,在你反应过来之前,整个公司都倒闭了,你不得不去甲骨文找一份新工作。而你本来仅仅需要做的就是确保你的负载生成系统能够胜任!
这就是为什么我认为了解负载测试工具的性能是非常有趣的。我认为每个使用负载测试工具的人都应该对它在性能方面的优缺点有一些基本的了解,并且偶尔还要确保他们的测试设置能够产生压测目标系统所需的流量。
测试测试工具
测试测试工具的一个好方法是不要在你的代码上测试它们,而是在一些性能肯定非常高的第三方软件系统上进行测试。我通常启动 Nginx 服务器,然后通过获取默认的“欢迎使用 Nginx”页面来进行测试。并且,使用像 top 这样的工具在测试时跟踪 Nginx CPU 使用情况是很重要。如果你只看到一个进程,
并且发现它的 CPU 使用率接近 100%,这意味着你可能在目标端受到 CPU 限制。然后你需要重新配置 Nginx 以使用更多的工作线程。
如果你看到多个 Nginx 进程但只有一个正在使用大量 CPU,这意味着你的负载测试工具仅与该特定工作进程通信。然后,你需要弄清楚如何使该工具打开多个 TCP 连接并在它们之上并行发出请求。
考虑到网络延迟也很重要,因为它钉死了每秒可以推送的请求数的上限。如果服务器 A(运行负载测试工具的地方)和服务器 B(Nginx 服务器所在的地方)之间的网络往返时间为 1 毫秒,并且你只使用一个 TCP 连接发送请求,那么你将能够达到的理论最大值是 1/0.001 = 每秒 1,000 个请求。在大多数情况下,这意味着你应该让负载测试工具使用许多 TCP 连接。
每当你碰到头,似乎无法继续增加 RPS 时,尝试找出达到瓶颈的资源。使用一些工具,例如 top,同时监控负载生成端和目标端的 CPU 和内存的使用情况。
如果两侧的 CPU 使用情况都很好,请尝试增加并发网络连接的数量,看看是否有助于提高 RPS。
另一个容易错过的事情是网络带宽. 例如,如果 Nginx 默认页面需要传输 250 字节来加载,这意味着如果服务器通过 100 Mbit/s 链接连接, 则理论上的最大 RPS 约为 100,000,000 除以 8(每字节位数)再除以 250 => 100M/2000 = 50,000 RPS。这还是一个非常保守的计算————协议开销会使实际数字低很多,所以在上述情况下,如果我发现 RPS 最大到了 30,000 左右,我会开始考虑带宽。 当然,如果接口碰巧在传输一些更大的资源,例如图像文件,这个理论上的最大 RPS (指 50,000)可能会低很多。如果你怀疑网络带宽变成瓶颈了,请尝试更改接口传输的文件的大小,看看 RPS 是否会随之改变。如果你将文件大小加倍并发现 RPS 降了一半,那你的怀疑是正确的。
最后,服务器内存也可能是一个瓶颈。通常,当你用完内存时,迹象非常明显,因为大多数东西都会停止工作,而操作系统会疯狂地尝试将辅助存储用作 RAM(即虚拟内存)。
经过一些实验后,你将确切知道如何从负载测试工具中获得最高 RPS,并且你将知道它在当前硬件上的最大流量生成能力是多少。当你了解了这些事情后,你就可以开始测试你想要测试的真实系统,并且现在每当你看到某 API 端点的 RPS 达到瓶颈时,你就能确信问题出在目标端,而不是负载生成端。
关于基准测试
上面的过程或多或少是我在测试这些工具时所经历的。我使用了一个小型、无风扇、8GB RAM、4 核 Celeron 服务器,运行着 Ubuntu 18.04,作为负载生成器机器。我想要就是这样多核但没那么强大的机器。因为我希望的是目标端的流量处理能力比负载生成端的流量生成能力更强(否则我测试的将不是负载生成端工具的能力了)。
对于目标端,我使用了具有 16G RAM 的 4Ghz i7 iMac。我确实使用了与开发机相同的机器,在其上运行了一些终端窗口并在浏览器中打开了一个谷歌电子表格,但确保了在测试运行时没有任何消耗性能的应用在运行。由于这台机器有 4 个非常快的超线程内核(能够并行运行 8 个应用),应该有足够的处理能力,但为了稳妥起见,我在不同的时间点重复了所有测试多次,只是为了验证结果是稳定的。
这些机器通过千兆以太网连接到同一个物理 LAN 交换机。
实际测试表明,该目标端足够强大,可以测试所有工具,但可能有一个例外。Wrk 设法产生了超过 50,000 的 RPS,这使得目标系统上的 8 个 Nginx 工作进程消耗了大约 600% 的 CPU。可能 Nginx 无法获得比这更多的 CPU 使用率(鉴于 800% 的使用率应该是具有超线程的 4 核 i7 的理论最大值),但我认为这并不重要,因为 Wrk 在流量生成方面属于 T0 级别。我们真的不需要知道 Wrk 是比 Artillery 快 200 倍,还是只快 150 倍。重要的是要表明目标系统可以处理大多数工具无法实现的一些非常高的 RPS 数,因为这样一来我们就知道,我们实际上是在测试负载生成端而不是目标系统。
原始数据
有一个包含所有测试的原始数据和文本注释的电子表格。实际上运行的测试比电子表格中的更多的————例如,我运行了很多测试来找出实现最大 RPS 的理想的工具参数。为了压榨每个工具以达到尽可能大的 RPS,需要进行一些探索性测试。此外,每当我觉得需要确保结果看起来稳定时,我都会再次运行一组测试并与我记录的结果进行比较。我可以很高兴地说结果的波动通常很小。我确实遇到了一次问题,突然间无论使用哪种工具,重新测试产生的性能数字都明显低于以前,最终我重新启动了负载生成机器,从而解决了问题。
测试的原始数据可以在这里找到。
我关心的指标
最大流量生成能力
在此实验环境中,每个工具每秒可以生成多少个请求?在这里,我尝试使用大多数可用参数,但主要是改变并发用户数(该工具使用了多少线程,或多少 TCP 连接)以及启用 HTTP keep-alive,禁用该工具所做的其他需要大量 CPU 的事情(比如 HTML 解析)等等。我们的目标是不惜一切代价让每个工具每秒尽可能多地产生请求!
我的想法是为每个工具测出一个基准线,以显示该工具在单纯生成流量时的效率。
每个 VU 的内存消耗
一些工具非常消耗内存,有时内存使用量也取决于测试中虚拟用户(VU)的规模。如果每个 VU 的内存消耗都很高,人们将很难使用该工具运行大规模测试,因此我认为这是一个有价值的性能指标。
每个请求的内存消耗
一些工具会在整个负载测试过程中收集大量统计信息。主要是在发出 HTTP 请求时,通常会存储各种时间指标。根据具体存储的内容以及存储方式的不同,这可能会消耗大量内存,并且会成为密集或长时间运行测试时的问题。
测量精度
所有工具都会在负载测试期间测量和报告响应时间。在这些测量中总会存在一定程度的误差————出于多种原因————但尤其是当负载生成器本身在做一些工作时,通常会发现响应时间测量值中添加了相当多的延迟。知道什么时候可以信任负载测试工具报告的响应时间测量值,什么时候不可以,是很有用的,而我已经尝试为每个不同的工具确定这个界限。
最大流量生成能力
这里有一张图,显示了我可以从每个工具中获得的最大 RPS 数值,以及对应的内存使用情况:
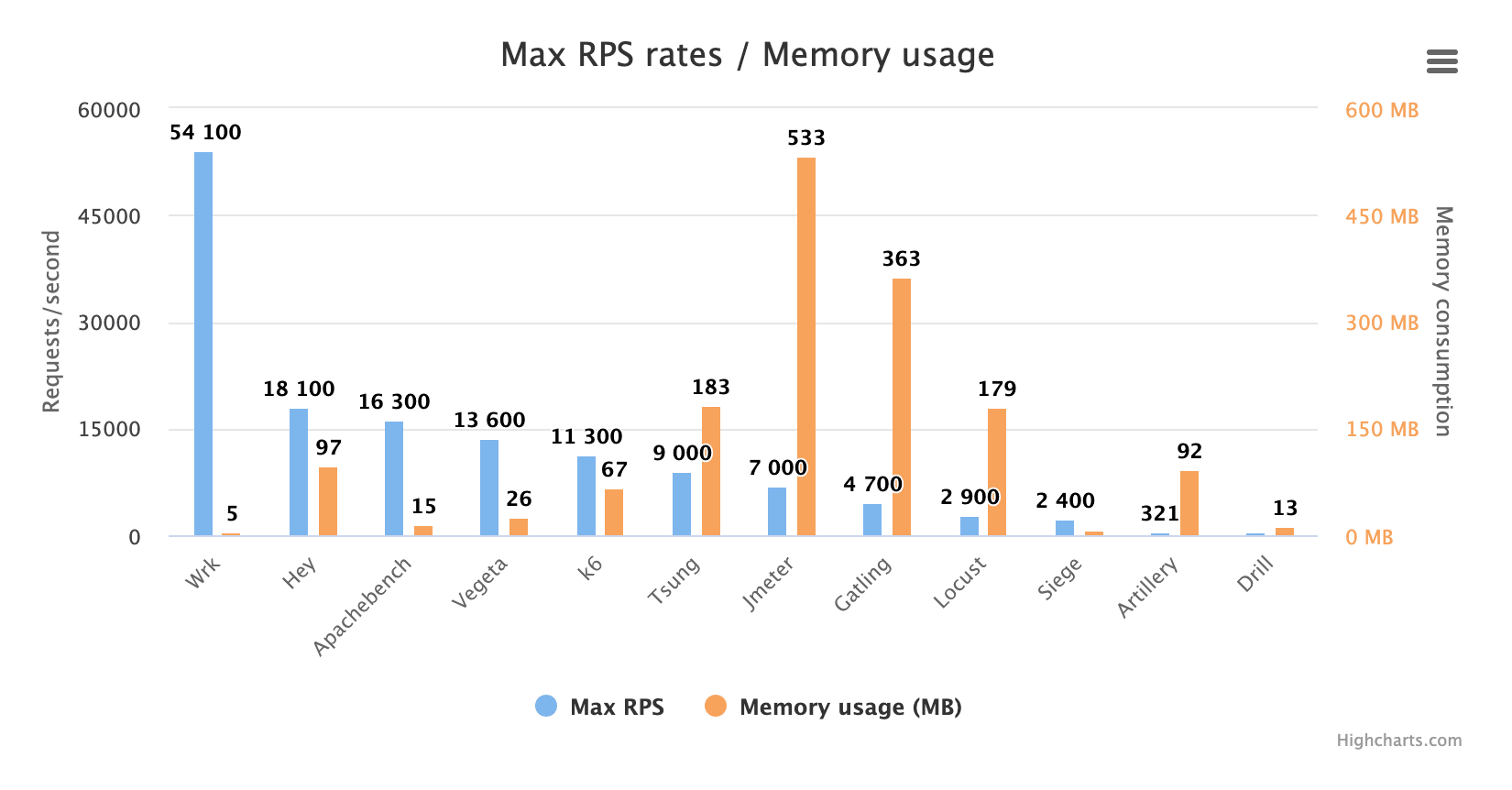
很明显,Wrk 吊打所有,它在生成流量方面是一头野兽。所以如果这就是你想要的————大量的 HTTP 请求————下载(并编译)Wrk。蹦,问题解决!
但是,作为一个了不起的请求生成器,Wrk 绝对不是在所有方面都完美的(参见前文的评论),所以看看其他工具的表现是很有趣的。让我们从图中删除 Wrk 以获得更好的比例:
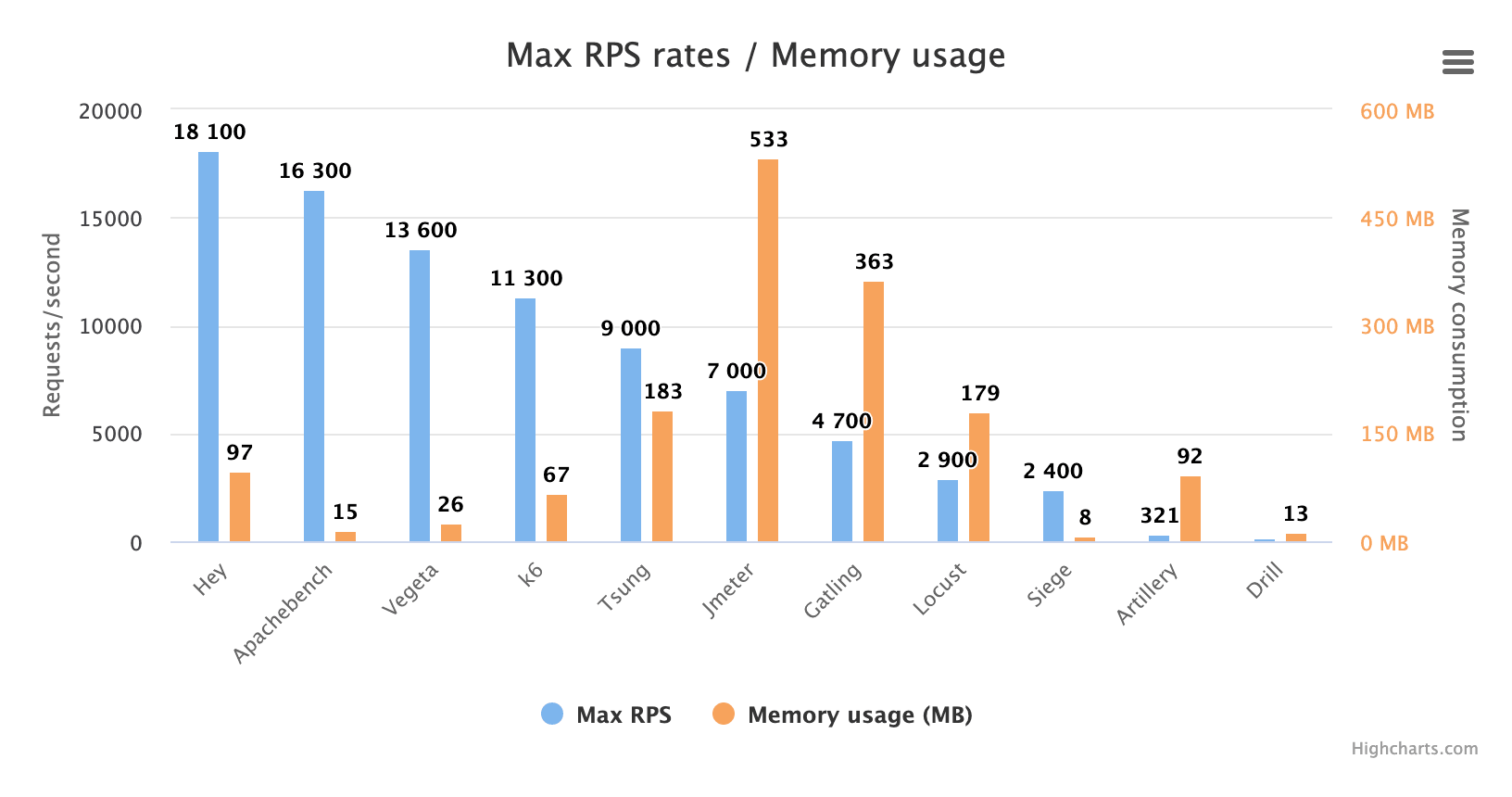
在讨论这些结果之前,我想提一下,有三个工具在非默认模式下运行,以生成尽可能高的 RPS 数:
Artillery
Artillery 以足够高的并发设置运行,以使其耗尽 CPU 内核,而这不被 Artillery 开发人员推荐,并导致来自 Artillery 的高 cpu 使用率警告。我发现用完完整的 CPU 内核会显著提高请求速率,从约 80% CPU 占用时的 100 RPS 出头到 100% CPU 使用率时的 300 RPS。当然,RPS 仍然非常低。 而且正如 Artillery FAQ 所说的那样,当 Artillery 耗尽 CPU 内核时,响应时间测量精度差到几乎无法使用————我们在响应时间准确性测试中将会看到详细状况。
k6
k6 在运行时启用 --compatibility-mode=base 命令行选项以禁用较新的 Javascript 特性,这导致你只能使用旧的 ES5 标准编写脚本。
它让内存使用量减少约 50% 并加速约 10%,这意味着最大 RPS 从约 10k 上升到约 11k。不过差别不大,我想说除非你碰到了内存瓶颈,否则不值得在运行 k6 时使用这种模式。
Locust
Locust 以分布式模式运行,这意味着启动了 5 个 Locust 实例:1 个主实例和 4 个从属实例(每个 CPU 内核一个从属实例)。Locust 是单线程的,因此不能利用多个 CPU 内核,这意味着你必须将负载生成分配给多个进程才能充分利用多 CPU 服务器上的所有 CPU(主从模式本应该集成进应用程序本身,以便它自动检测机器是否具有多个 CPU,是否需要启动多个进程)。如果我只在一个实例中运行 Locust,它将只能生成 900 左右的 RPS。
我们还为 Locust 的测试使用了新的 FastHttpLocust 库。这个库比旧的 HttpLocust 库快 3-5 倍。 但是,使用它意味着你会失去一些 HttpLocust 具有但 FastHttpLocust 没有的功能。
自 2017 年以来发生了什么变化?
我不得不说这些结果一开始让我有点困惑,因为我在 2017 年测试了这些工具中的大部分,并且预计现在的性能几乎没变。当然,绝对的 RPS 数字无法与我之前的测试相比,因为当时我使用了另一个测试环境,但我预计工具之间的相对关系大致保持不变:例如,我认为 Jmeter 仍然是最快的工具之一,而且我认为在单个 CPU 内核上运行时,Artillery 仍然会比 Locust 更快。
Jmeter 变慢了!
好吧,正如你所看到的,Jmeter 的性能现在看起来相当普通。从我的测试来看,Jmeter 从 2.3 版本到我现在测试的版本 5.2.1,性能似乎下降了大约 50%。这本以为可能是 JVM 的问题。于是我使用 OpenJDK 11.0.5 和 Oracle Java 13.0.1 分别进行了测试,两者的性能几乎相同,因此这似乎不太可能是由于 JVM 较慢。我也尝试过提高 -Xms 和 -Xmx,这是确定 JVM 可以分配多少内存的参数,但这也不会影响性能。
Artillery 现在慢多了,Locust 则快多了!
至于 Artillery,现在它似乎也比两年前慢了大约 50%,这意味着它现在和两年前的 Locust 一样慢,而当时我无休止地抱怨 Locust 有多慢。Locust 呢? 它是唯一一个自 2017 年以来性能有显著提高的工具。由于其新的 FastHttpLocust HTTP 库,它现在的速度比当时快了大约 3 倍。 这确实意味着牺牲了旧的 HttpLocust 库(它基于非常用户友好的 Python Requests 库)提供的一些功能,但我还是对 Locust 的性能提升非常满意。
Siege 变慢了!
尽管是用 C 编写的,两年前 Siege 就不是一个很快的工具,但不知何故,它的性能似乎在 4.0.3 和 4.0.4 版本之间进一步下降, 所以现在它比基于 Python 的 Locust 慢,而后者是以分布式模式运行,可以在单台机器上使用所有 CPU 内核。
Drill 慢的跟乌龟一样
Drill 是用 Rust 编写的,所以理应非常快,并且它很好地利用了所有 CPU 内核,这些内核在测试期间始终非常忙碌。然而,没有人知道这些核心在做什么, 因为 Drill 只能产生令人难以置信的 176 RPS!这与 Artillery 差不多,但 Artillery 只使用一个 CPU 核心,而 Drill 使用四个! 我本想看看 shellscript 是否可以产生与 Drill 一样多的流量。答案是“是的,差不多”。你可以自己试试:curl-basher。
Vegeta 终于可以进行基准测试了,而且还不错!
Vegeta 过去没有提供控制并发用户数的方法,这使得它很难与其他工具进行比较,因此在 2017 年我没有将它包含在基准测试中。
不过,现在它有了一个 -max-workers 开关,可用于限制并发用户数,加上 -rate=0(不限制 RPS)选项后我就可以像测试其他工具一样对其进行测试了。我们可以发现 Vegeta 的性能非常好————它既能产生大量流量,又只占用很少的内存。
其余工具的性能与 2017 年大致相同。
总结流量生成能力
我想说的是,如果你需要产生大量流量,图表左侧的那些工具可能会更称职,因为它们效率更高,但大多数情况下 Gatling、Siege 或分布式 Locust 所能产生的每秒几千个请求就绰绰有余了。但是,除非你是受虐狂或想要额外的挑战,否则我建议你不要使用 Artillery 或 Drill。用这些产生足够的流量会很棘手,而且当测量值出现偏差时解释结果也很棘手(至少 Artillery 是这样的),因为你必须榨干负载生成器上的 CPU。
内存消耗情况
那么内存消耗情况呢?让我们再次拿起统计图:
贪得无厌的内存消耗大户是 Tsung、Jmeter、Gatling 和 Locust。尤其是我们亲爱的 Java 应用程序————Jmeter 和 Gatling————真的很能吃内存。 如果 Locust 不必在多个进程中运行(因为它本身是单线程的),那么它的表现不会这么糟糕。多线程应用程序可以在线程之间共享内存,但多个进程被迫保留相同的大量数据集。
这些数字表明了这些工具对内存的消耗程度,但别被数字骗了。毕竟,今天的 500 MB 算多少?几乎没有任何服务器不是有几 GB 的 RAM,因此 500 MB 绝不应该是什么大问题。但是,问题是,当你扩大测试规模时,内存使用量是否会增加。有两件事会使内存使用量增加:
- 长期运行(会收集大量结果数据)
- 增加 VU / 执行线程的数量
为了调查它们,我运行了两套测试分别来测量“每个 VU 的内存消耗”和“每个请求的内存消耗”。我实际上并没有尝试计算每个 VU 或请求的确切内存消耗量,而是使用越来越多的请求和 VU 运行测试,并记录内存使用情况。
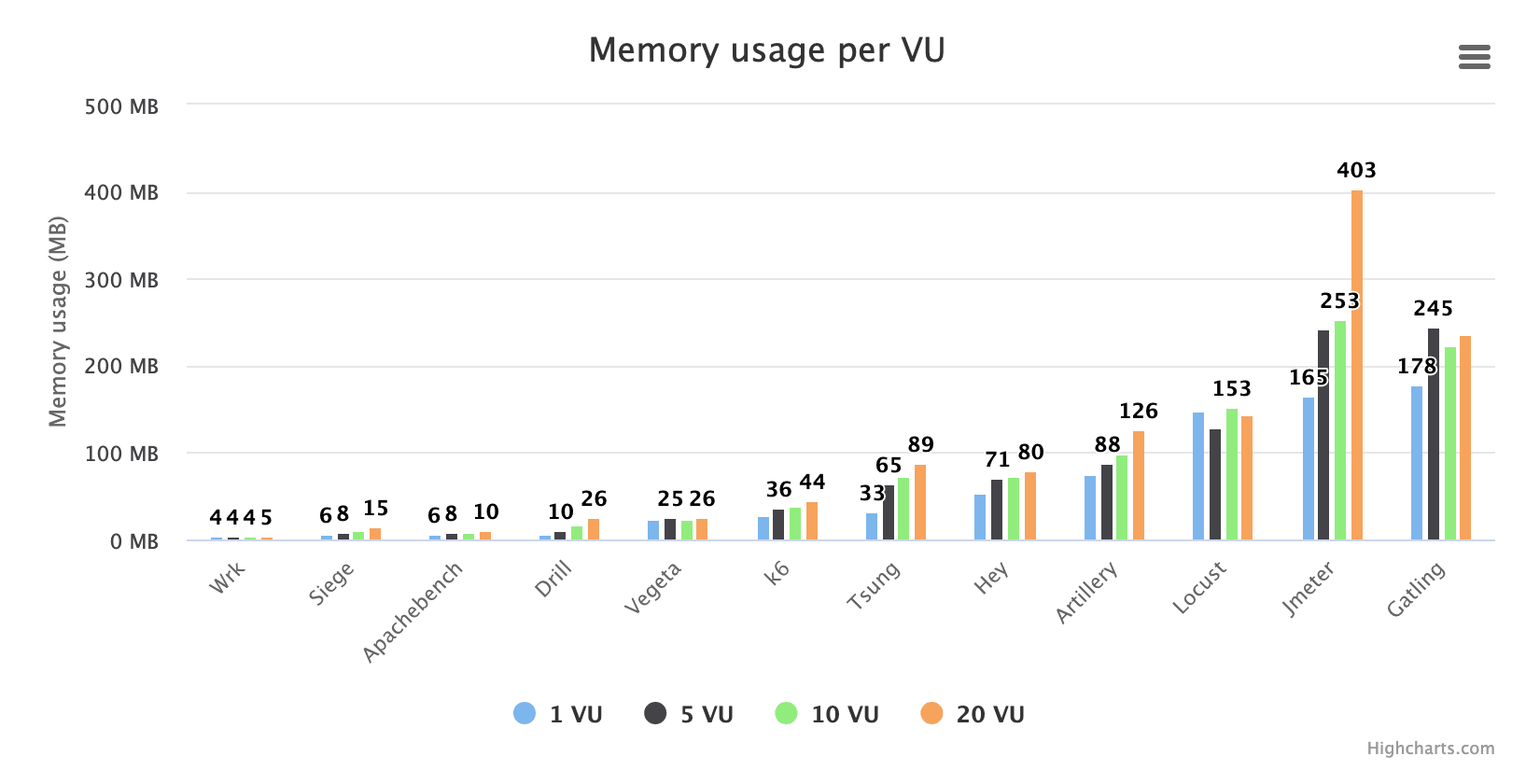
在这里,我们可以看到当你增大虚拟用户(VU)的数量时会发生什么。请注意,显示的数字是整个非常短(10 秒)的测试中的平均内存使用量。测试期间每秒采样一次,因此通常采样 9-10 个。这个测试真的应该用更多的 VU 来完成,也许从 1VU 到 200 VU 什么的,并且让 VU 别做太多事,这样你就不会得到太多的结果数据。这样,当你尝试模拟更多用户时,你会真正感受到这些工具的扩展性如何。
但我们可以在这里发现一些东西。当我们更改 VU 数量时,一些工具似乎没有受到影响,这表明它们的每个 VU 只使用少量内存,或者它们分块分配内存,而我们在此测试中没有配置足够多的 VU 以迫使它们分配比开始时更多的内存。你还可以看到,使用 Jmeter 之类的工具,当你尝试扩大测试规模时,内存不太可能成为问题。如果你尝试从这些非常少的状态开始大幅增加 VU 数量,Tsung 和 Artillery 看起来也可能最终会使用大量内存。
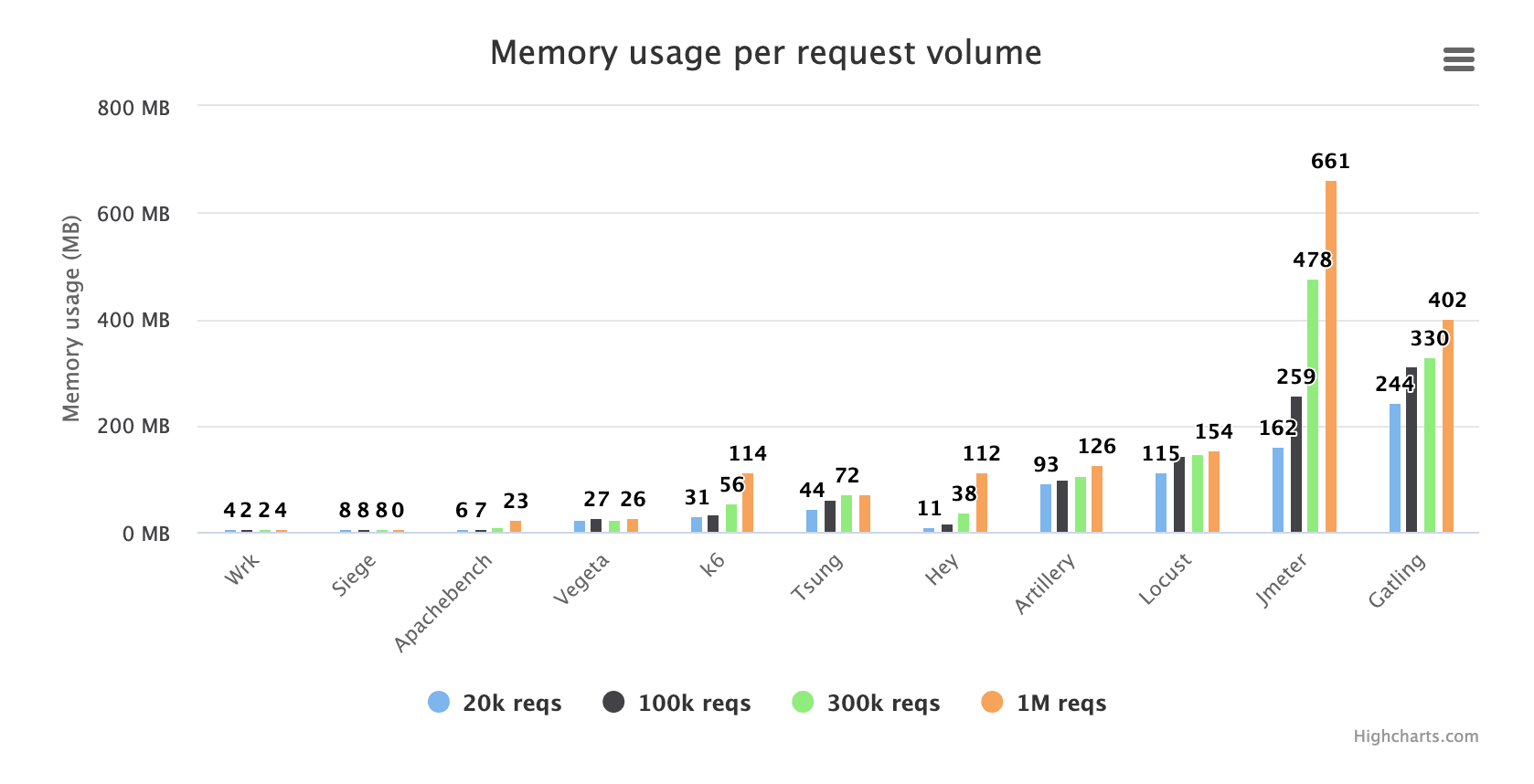
对于此测试,我使用相同的 VU 参数运行所有工具,但改变测试持续时间。我的想法是让这些工具收集大量结果数据,并查看随着时间的推移内存使用量增加了多少。该图显示了当每个工具从存储 20k 事务结果到 100 万个结果时,它的内存使用量变化了多少。
正如我们所看到的,Wrk 并没有真正使用多少内存。再强调一次,它同时也不存储太多结果数据。Siege 在内存方面似乎也很节俭,但我们未能测试 100 万个事务, 因为 Siege 在我们达到 1m 之前挂掉了。这倒没有出乎意料,因为 Siege 每个 TCP 套接字只发送一个请求————然后它关闭套接字并为下一个请求打开一个新的。这会使系统缺乏可用的本地 TCP 端口。如果你使用 Siege,你最好有心理准备:任何更大或更长时间的测试都很可能失败。
随着测试的进行,Tsung 和 Artillery 的内存使用量似乎有所增加,但增加速度并不快。k6 和 Hey 的曲线要陡峭得多,在长时间运行的测试中,你最终可能会遇到麻烦。
同样,消耗大量内存的是 Java 应用程序:Jmeter 和 Gatling。当 Jmeter 执行了 100 万个请求时,它的内存大小从 160MB 变为 660MB。请注意,这是整个测试中的平均内存使用量。测试结束时的实际内存使用量可能是其两倍。当然,JVM 可能根本不进行 GC,直到它觉得有必要————我不确定它是如何工作的。但是,如果真的如此,那么 JVM 在测试期间的某个时间点假如确实必须进行一些相当大规模的 GC,性能会有抖动吗?这可能值得进一步研究。
哦,Drill 被踢出测试队伍之外。使用 Drill 生成 100 万次请求花费了巨长时间。我的孩子会在测试期间长大。
测量精度
有时,当你运行负载测试并用巨量流量冲击目标系统时,目标系统将开始产生错误。请求将偶尔失败,并且目标系统本应提供的服务将对某些(或所有)用户不再可用。
然而,这通常不是首先发生的事情。当系统承受重负载时,往往会发生的第一件坏事就是速度变慢。或者,更准确地说,请求会排队,对用户的服务会变慢。请求不会像以前那样快速完成。即使服务仍在运行,这还是会导致更差的用户体验。在这种性能下降不多的情况下,用户对服务的满意度会有所降低,这意味着有些用户会流失,不再使用所提供的服务。在性能下降严重的情况下,其影响可能是或多或少的总收入损失,例如对于电子商务网站。
这意味着测量请求响应时间非常有价值。你会希望能确保在预期流量下响应时间仍可接受,并记录它们的值,以便利用回归测试确保响应时间不会随着新代码的加入而倒退。
所有负载测试工具都尝试在测试期间测量请求响应时间,并为你提供有关它们的统计信息。但是,总会有测量误差。误差通常表现为测量值大于真实客户所经历的实际响应时间。或者,换一种说法,负载测试工具通常会报告比真实客户经历的更糟糕的响应时间。
这个误差到底有多大取决于多种因素。它一方面取决于负载生成端的资源利用率————例如,如果你的负载生成机器正在使用其 100% 的 CPU,我敢打赌响应时间测量将非常不稳定。另一方面,误差在工具之间也有很大差异————一种工具总体上可能会产生比另一种工具低得多的测量误差。
作为用户,我希望误差尽可能小,因为如果它很大,它可能会在回归测试中掩盖目标系统的性能退化问题。此外,它可能会误导我,让我误认为是目标系统响应速度不够快,无法满足我的用户。
以下图表显示了不同工具在 VU 不同时报告的响应时间:
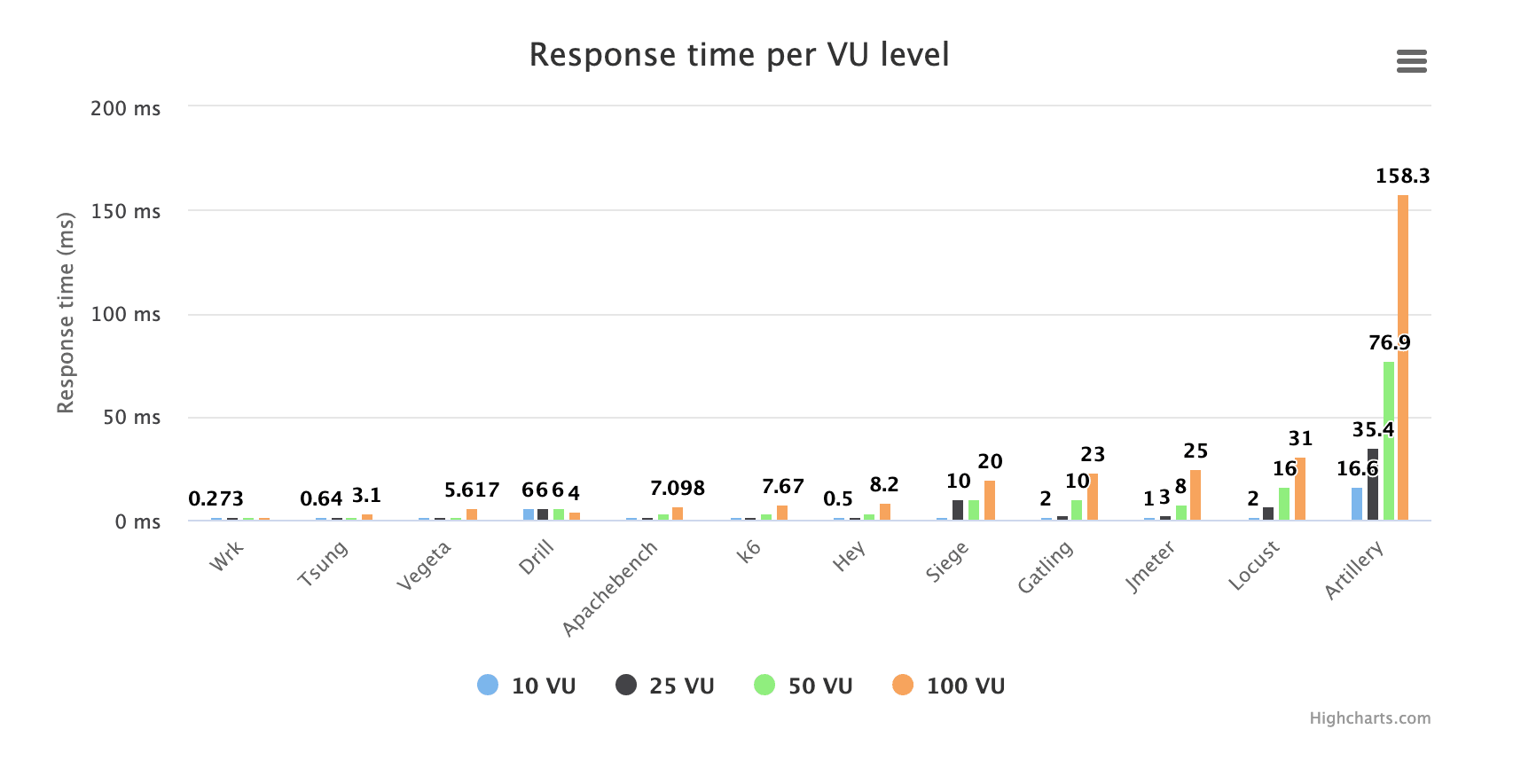
正如我们所看到的,一个名字为军事术语的工具会大大增加图表的比例,以至于很难比较其他工具。我已经在本文其他地方彻底抨击了它,因此,我将删除违规者。现在我们得到:
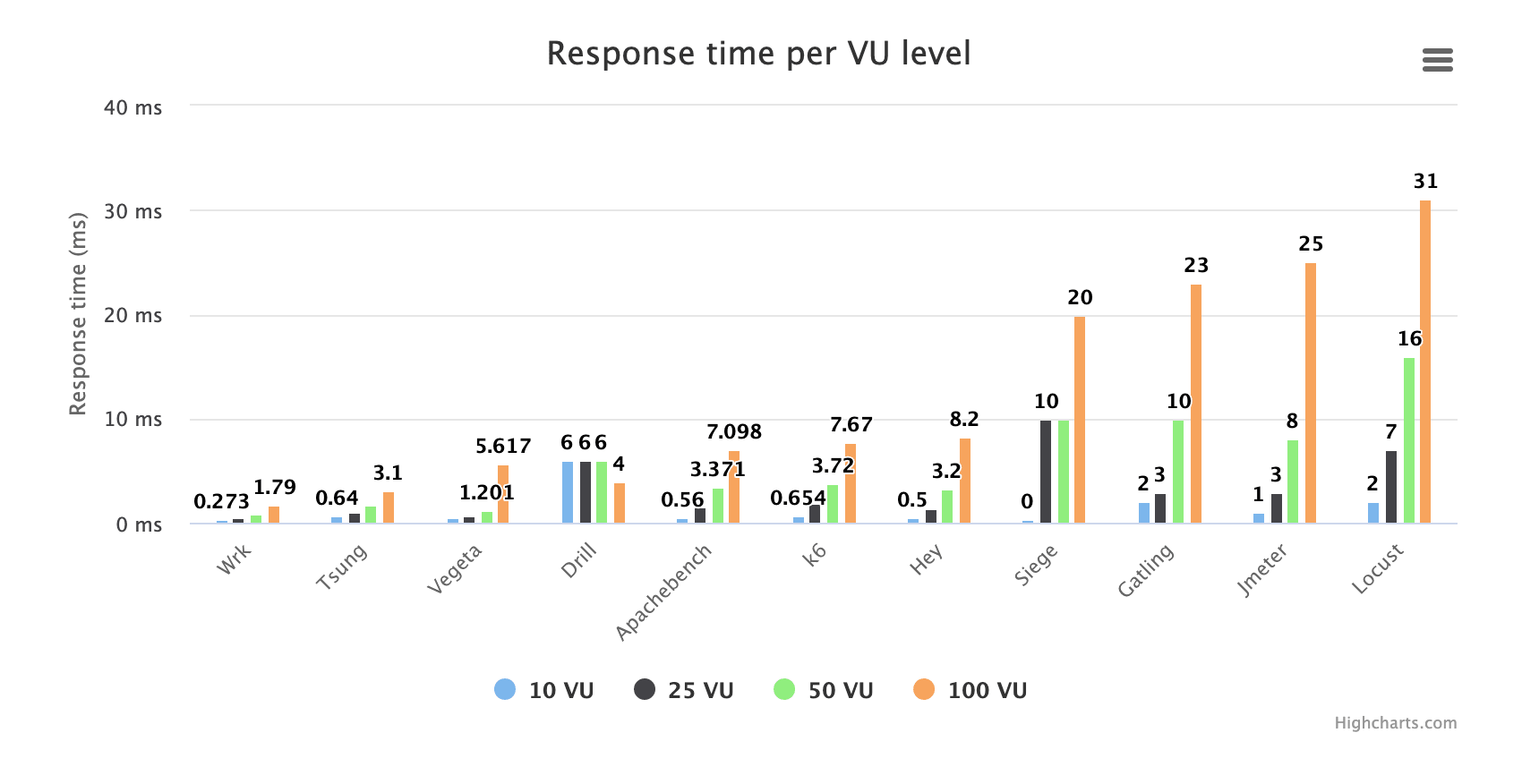
好的,现在看上去好多了。首先也许需要解释一下这个测试做什么。我们以设定的 VU 运行每个工具,尽可能快地生成请求。即请求之间没有延迟。 根据工具和 VU 不同,请求速率从 150 RPS 到 45,000 RPS 不等。
如果我们首先查看作弊者————Wrk————我们会看到随着我们将 VU 从 10 增加到 100,它的 MEDIAN(所有这些响应时间都是中位数)响应时间从约 0.25ms 增加到 1.79ms。这意味着在 VU 为 100(100 个并发连接同时发出请求)和 RPS 为 45,000(这是 Wrk 在此条件下实现的)时,实际服务器响应时间低于 1.79 毫秒。因此,在这样的 VU 上,任何工具报告的超过 1.79 毫秒的延迟都非常肯定是负载测试工具本身添加的延迟,与目标系统无关。
你可能会问为什么用中值响应时间?为什么不是 TP99 之类的,这通常更能反应响应时间的真实状况。这仅仅是因为中值是唯一一个所有工具都会报告的指标(除了“最大响应时间”)。一个工具可能会报告 TP90 和 TP95,而另一个工具可能会报告 TP75 和 TP99。甚至不是所有工具都报告平均响应时间(我知道这是一个糟糕的指标,但它本是一个非常常见的指标)。
图横轴中间的工具在同样的 100 VU 时报告了 7-8 ms 的中位响应时间,比 Wrk 报告的 1.79 ms 高约 5-6 ms。这使得我们可以合理地假设,在此并发用户数上,普通工具测量响应时间时会多报约 5 毫秒。当然,一些工具(例如 Apachebench 和 Hey)在多报了这么点响应时间的同时设法生成了大量 HTTP 请求。其他的————比如 Artillery————只能生成非常少量的 HTTP 请求,却仍然会产生非常大的测量误差。让我们再看一个图,它同时显示 RPS 与中值响应时间测量值。请记住,这里的目标端可能或多或少总能实现小于 1.79 毫秒的实际中值响应时间。
让我们看看每个工具测量的响应时间与生成的 RPS 的关系,因为这可以揭示该工具在生成多大 RPS 时仍然能提供可靠的测量结果。
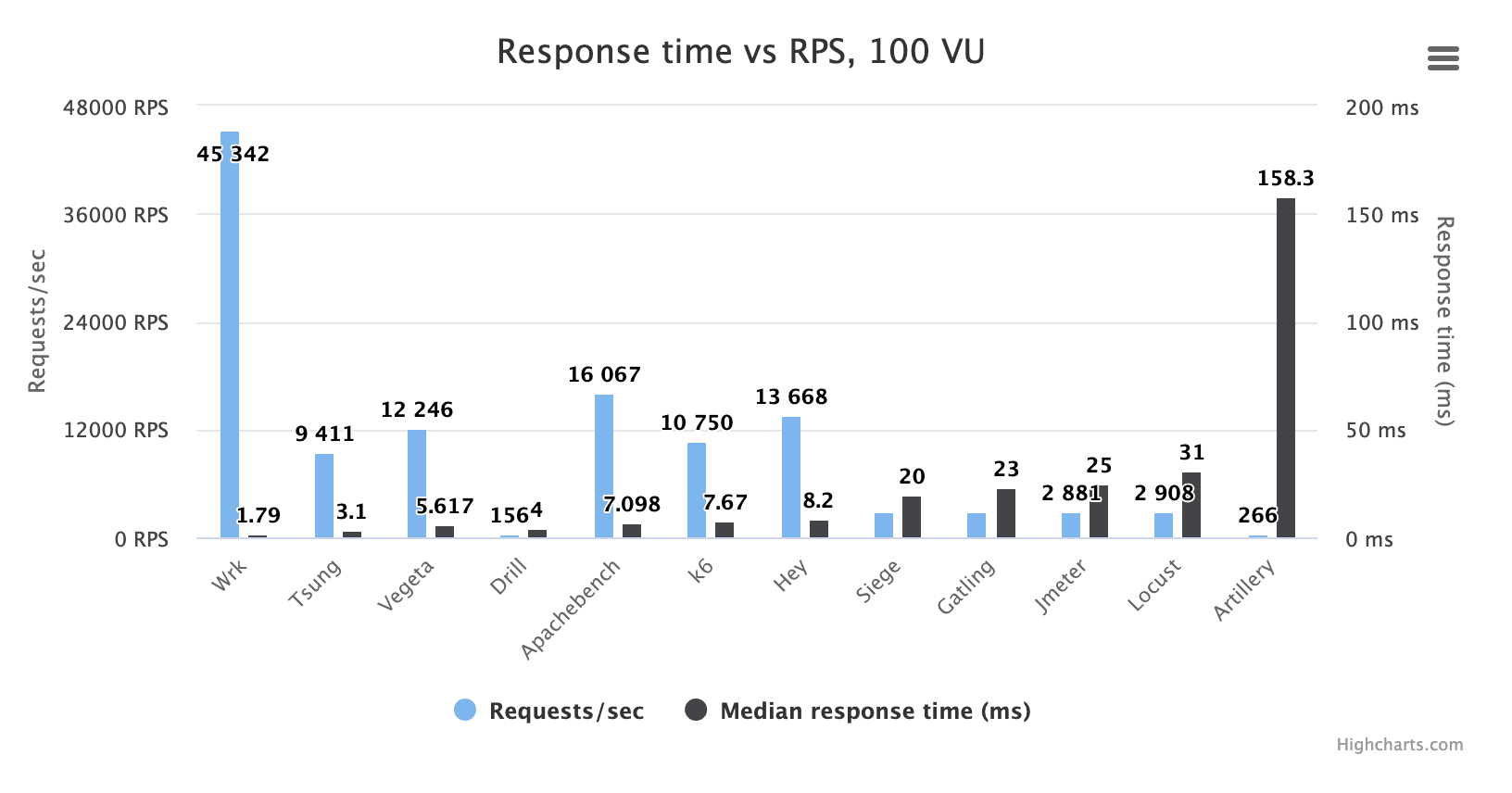
同样,Artillery 远远落后于其他工具,出现了大约 150ms 的巨大测量误差,而每秒只能发出少于 300 个请求。而 Wrk,输出 150 倍的流量,同时产生 1/100 的测量误差,你会感到性能最好和性能最差的工具之间的差异到底有多大。
我知道喜欢 Artillery 的人会说“但这只是因为你不顾 Artillery 发出的高 CPU 使用率警告,让它用完了所有的 CPU”。好吧,我还进行了一项测试, 我降低了对 Artillery 的负载生成要求,以确保这警告从未出现过。我仍然使用了 100 个并发用户,但他们每个都运行带有内置睡眠的脚本,这保证 CPU 使用率保持在 80% 左右,并且没有出现任何警告。当然,RPS 最终要差得多————63 RPS。响应时间测量结果?43.4 毫秒。超过 40 毫秒的误差。
因此,即使 Artillery 运行“良好”并产生了惊人的 63 RPS————Wrk 能产生接近 1,000 倍的流量————它仍然会产生一个比 Wrk 的测量误差大 20 倍的误差。虽然我还没有真的测试过,但如果 curl-basher 在这个方面做得比 Artillery 更好,我不会感到惊讶。
让我们再次从图中删除 Artillery:
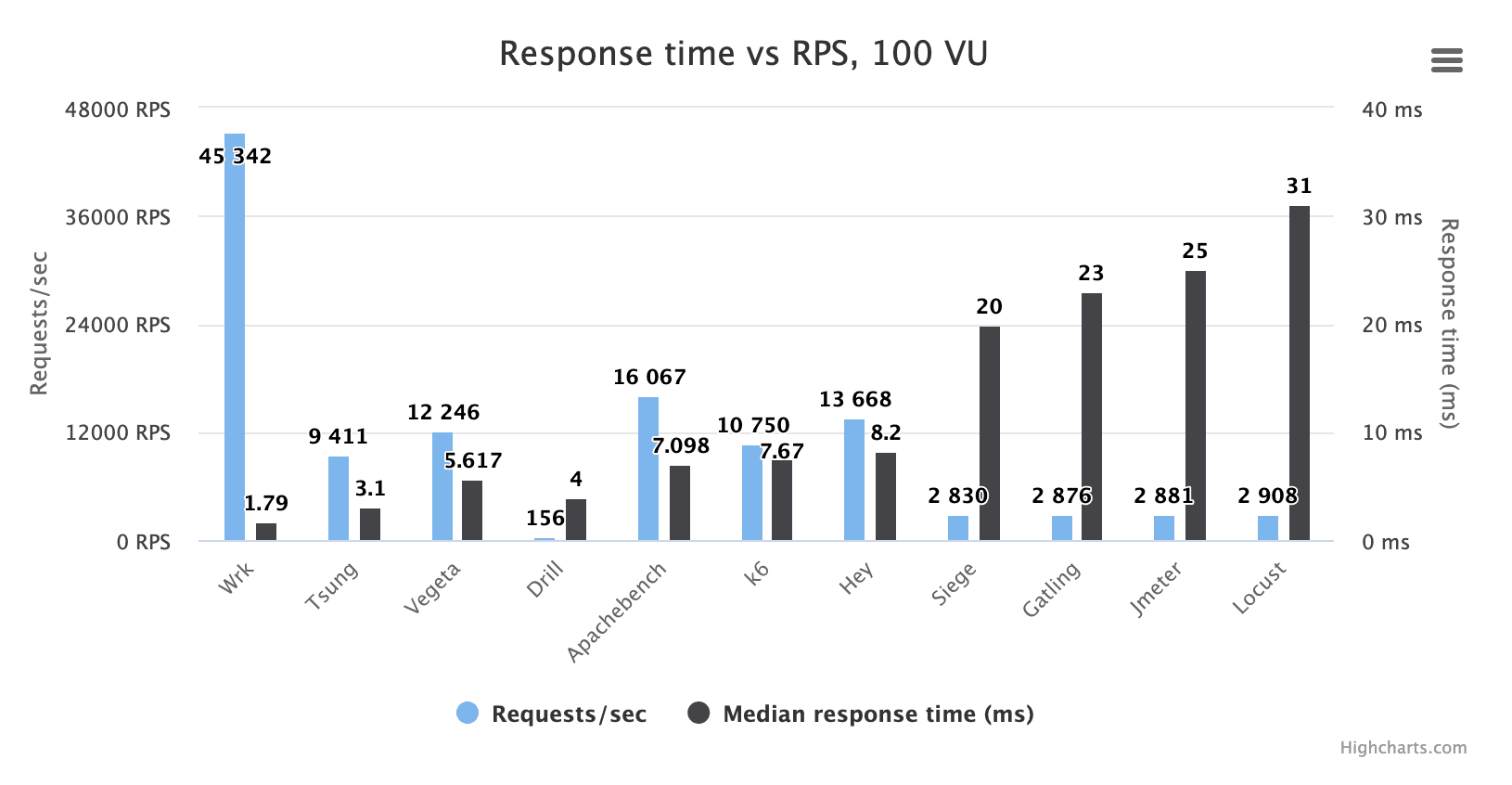
有趣的是,测量误差最高的四种工具(不包括 Artillery)在这里的表现非常相似:Siege、Gatling、Jmeter 和 Locust。在模拟 100 VU 时, 它们在我的环境中的 RPS 都低于 3,000,而且它们似乎都多报了相似数量的测量误差:在 20 到 30 毫秒之间。
Jmeter 曾经是基准测试中性能较高的工具之一,但在过去的 2-3 年中,它的性能似乎变得越来越差。Siege 也差了很多, 它现在的性能真让人猜不出来它是一个用 C 编写的工具。相反,基于 Python 的 Locust 已经迎头赶上了这些工具,它的流量生成能力已经追上来了,可惜正确测量能力还是略输一筹。
Tsung 再次令人印象深刻。虽然是一个古老且维护不那么积极的工具,但它的负载生成能力相当不错,而且测量精度首屈一指(当然,除了 Wrk)。
Drill 就是个怪胎。
Vegeta、Apachebench、k6 和 Hey 似乎都非常擅长生成流量,同时将测量误差保持在相当低的水平。你可以又要觉得我偏心了,但我很高兴看到 k6 在所有这些基准测试中都处于中间位置,因为它能执行复杂的脚本逻辑,而性能优于它的工具却不能。
最终总结
k6 必将加冕为王!
或者,嗯,就是这样,但其他大多数工具在某些方面也还不错。
- 我不是很喜欢 Gatling,但在“我需要一个更现代的 Jmeter”的场景中,我理解为什么其他人喜欢它。
- 当我需要一个简单的命令行工具来压测单个 URL 时,我喜欢 Hey。
- 在我需要一个更高级的命令行工具来压测一些 URL 时,我喜欢Vegeta。
- 我根本不喜欢 Jmeter,但我猜测非开发人员在需要一个可以做任何事情的基于 Java 的工具或 GUI 工具时,只会选择它。
- 我喜欢 k6 (显然),它适合开发人员的自动化测试。
- 假如我真的很想用 Python 编写测试用例,那就选择 Locust。
- 只有 Wrk 有能力狂暴轰入服务器!
然后我们列出几个似乎最好避免的工具:
- Siege 只是一个旧的、奇怪的、不稳定的、似乎没有维护的工具。
- Artillery 超级慢,测量不正确,开源版本似乎是个没娘的孩子。
- Drill 正在加速全球变暖。
祝你好运!