赋值语句
Python 的赋值语句值得考量。看下面的例子:
>>> a = [-1, -1]
>>> i = 0
>>> a[i] = i = i + 1
>>> a, i
([1, -1], 1)
>>> i = a[i] = i - 1
>>> a, i
([0, -1], 0)
对于这种链式赋值(chain assignment)的写法,有三点需要注意:
- 右侧表达式先求值
- 赋值从左向右进行
- 每次赋值前才开始解引用
对于第一次赋值 a[i] = i = i + 1,表达式 i + 1 先求值为 1,此后这个值就与 i 无关了,
接着 a[i] 解引用为 a[0] 并处理赋值 a[0] = 1,然后处理赋值 i = 1。
而对于第二次赋值 i = a[i] = i - 1,表达式 i - 1 同样先求值为 0,
接着处理赋值 i = 0,然后才开始解引用 a[i],因为第一次赋值已经改变了 i,所以现在 a[i] 解引用为 a[0],
并处理赋值 a[0] = 0。
事实上:
x = y = some_function()
# 等价于
temp = some_function()
x = temp
y = temp
# 而不等价于
y = some_function()
x = y
# 或
x = some_function()
y = some_function()
同样的道理在平行赋值(parallel assignment)中也适用:
# 反转链表
class Solution:
def reverseList(self, node: ListNode) -> ListNode:
head, cur = None, node
while cur:
# right
cur.next, cur, head = head, cur.next, cur
# wrong, AttributeError: 'NoneType' object has no attribute 'next'
cur, cur.next, head = cur.next, head, cur
return head
右边的多个表达式先分别求值得到对应的结点,再从左到右解引用并赋值。
如果 cur 的赋值发生在 cur.next 的解引用与赋值之前的话,语义就不是我们想要的了,且会发生错误。
平行赋值的实质是:右侧是省略了括号的元组表达式(pack),左边则是在解包(unpack)。
更多内容可以参考文档或相关书籍。
数字
Python 3 中的 int 没有大小限制,所以不需要防止溢出。
但是如果你需要一个足够大的数字(比如说作为答案变量 ans 的初始值,
这个变量后续会通过 ans = min(ans, x) 更新),
你可以用 sys.maxsize。它不是 int 的上限,
但确是当前平台的 list、string 等的最大长度(因此它的值根据平台不同而不同),通常程序使用的合理的整数不会大于它。
对于整数 x 与 y,x / y 返回浮点数;假设 z = x / y,math.ceil(z) 返回大于等于 z 的最小整数,
而 math.floor(z) 返回小于等于 z 的最大整数;更常用的,x // y 等价于 math.floor(x / y)。
>>> -1 / 5
-0.2
>>> import math
>>> math.ceil(-0.2)
0
>>> -1 // 5
-1
内置函数 round() 可以进行“四舍六入五成双”操作。
>>> round(3.44)
3
>>> round(1.5)
2
>>> round(0.5)
0
>>> round(-0.5)
0
字符串与字符
字符串是常量,不能修改,但是可以通过 list() 将其转化成字符列表再操作列表。
这其实是因为 list() 接收 iterable,而字符串就是元素为字符的 iterable。
字符串的常用方法有:
s.startswith(prefix)检查字符串是否以prefix开头s.endswith(suffix)检查字符串是否以suffix结尾s.find(sub)返回sub第一次出现的索引;若不存在,返回 -1s.count(sub)返回sub在s里面出现的次数s.replace(old, new)返回一个新字符串,原串中所有的old在新串中均替换为news.isdigit()测试s是否不为空串且只包含数字字符s.lower()返回一个新字符串,原串中所有大写字符在新串中均转换为小写s.upper()返回一个新字符串,原串中所有小写字符在新串中均转换为大写s.lstrip()返回一个新字符串,其中截掉了原串左边的空格s.rstrip()返回一个新字符串,其中截掉了原串右边的空格s.strip()返回一个新字符串,其中截掉了原串左右两边的空格s.join(iterable)以s作为分隔符,将iterable中所有的字符串合并为一个新的字符串s.split(separator)返回一个list,其中包含原串以separator为分隔符分割出的所有子串,子串数等于separator出现次数加一,如果separator出现在首尾或连续出现,会分割出空串
合并字符串可以使用 s1 + s2 + s3,但是它会生成多余的字符串,效率不高;
join() 方法更加常用。但是这两种写法都只能合并字符串,其他类型变量必须手动转换为字符串才能进行合并。
不过我们可以用 format() 方法或等效的 F-strings 写法直接进行变量插值。
>>> ''.join([1, 2])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sequence item 0: expected str instance, int found
>>> '{}{}'.format(1, 2)
'12'
>>> '{a}{b}'.format(b = 2, a = 1)
'12'
>>> a, b = 1, 2
>>> f'{a}{b}'
'12'
内置函数 str() 会调用对象的 __str__() 方法,返回其字符串表示。
所以可以用它将整数或浮点数转换成字符串。
反过来,你可以用内置函数 int() 将字符串转成整数,用 float() 将字符串转成浮点数。
>>> int('23')
23
>>> int('111', 2)
7
>>> int('0b111', 2)
7
>>> int('fa', 16)
250
>>> float('23.4')
23.4
Python 中没有字符类型,但是我们可以把长度为 1 的字符串看成字符。
利用内置函数 chr() 与 ord() 我们可以进行 Unicode 字符与对应整数间的转换。
>>> chr(97)
'a'
>>> ord('a')
97
>>> ord('或')
25110
>>> ord('abac')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: ord() expected a character, but string of length 4 found
列表(list)
列表可以当成是变长数组来用。
它的常用方法有:
l.append(e)在列表末尾添加新的元素l.extend(iterable)在列表末尾一次性追加另一个序列中的多个值l.index(e)从列表中找出某个值第一个匹配项的索引位置l.insert(index, e)将元素插入列表指定位置l.pop([index=-1])移除列表中的一个元素(默认最后一个元素),并且返回该元素的值l.remove(e)移除列表中某个值的第一个匹配项l.count(e)统计某个元素在列表中出现的次数l.reverse()反向列表中元素l.sort(key=None, reverse=False)对列表进行排序l.clear()清空列表
list 可以当作栈,但是最好不要当作队列,因为 l.pop(0) 的时间复杂度为 O(N)。
你可以改用双端队列 deque。
l.reverse() 与 l.sort(key=None, reverse=False) 是原地修改,
而 reversed(l) 与 sorted(l, key=None, reverse=False) 不影响传入的 iterable 参数本身,
其中 reversed(l) 还是一个 O(1) 的函数,只会返回一个 iterator。
下面的写法可以快速初始化一个指定大小的数组,但是注意它会进行浅拷贝,直接下层的元素不能是引用:
>>> li = [0] * 5
>>> li[2] = 1
>>> li
[0, 0, 1, 0, 0]
>>> li = [set()] * 5
>>> li[2].add(1)
>>> li
[{1}, {1}, {1}, {1}, {1}]
这种错误很容易发生在初始化二维数组时:
# wrong
matrix = [[0] * n] * m
# right
matrix = [[0] * n for _ in range(m)]
双端队列(deque)
collections 包中的 deque(发音是 “deck”,“double-ended queue”的简称) 是一个双端队列。它的初始化方法 deque([iterable[, maxlen]]) 根据 iterable 创建队列,
从左到右初始化(用方法 append()),如果 iterable 没有指定,新队列为空。如果 maxlen 没有指定或者是 None,
deque 可以增长到任意长度;否则,deque 就限定到指定最大长度,一旦限定长度的 deque 满了,当新项加入时,同样数量的项就从另一端弹出。
deque 支持线程安全,内存高效的添加(append)和弹出(pop),从两端都可以,两个方向的大概开销都是 O(1) 复杂度。
虽然 list 也支持类似操作,不过它的 pop(0) 和 insert(0, e) 会引起 O(N) 的内存移动。
deque 支持下标引用,例如通过 q[0] 访问首个元素等;索引访问在两端的复杂度均为 O(1) 但在中间则会低至 O(n)。
如需快速随机访问,请改用列表。
deque 对象主要支持以下方法:
q.append(e)添加e到右端q.extend(iterable)扩展deque的右侧,添加iterable参数中的元素q.appendleft(e)添加e到左端q.extendleft(iterable)扩展deque的左侧,添加iterable参数中的元素;注意,左添加时,在结果中iterable参数中的顺序将被反过来q.pop()移去并且返回最右侧的一个元素,如果没有元素的话,就引发一个IndexErrorq.popleft()移去并且返回最左侧的一个元素,如果没有元素的话,就引发IndexErrorq.clear()移除所有元素q.count(e)计算deque中元素等于e的个数q.index(e)返回e在deque中第一次出现的位置,如果未找到则引发ValueErrorq.insert(i, e)在位置i插入e,如果插入会导致一个限长deque超出长度maxlen的话,就引发一个IndexErrorq.remove(e)移除找到的第一个e,如果没有的话就引发ValueErrorq.reverse()将deque逆序排列,返回None
堆(heap)
Python 对堆的支持比较奇怪,它提供的不是数据结构,而是算法。
heapq.heapify(li) 在线性时间内原地把传入的列表变成堆。
默认是最小堆,堆顶通过 li[0] 可以获取,如果需要最大堆且堆内元素为数字,可以尝试把元素全变成相反数。
不同于 reversed() 与 sorted(),堆不支持通过参数 key 指定排序的依据,
一般我们都是通过把元素写成元组 (priority, item) 来实现这种需求的。
heapq.heappush(li, item) 把元素添加进 heap,heapq.heappop(li) 弹出堆顶,这两个操作会相应的导致堆大小变化;
heapq.heappushpop(li, item) 依次完成两个操作,保持堆大小不变,而且它比手动组合两个操作执行地要快。
>>> li = [2, 1, 4]
>>> import heapq
>>> heapq.heapify(li)
>>> li
[1, 2, 4]
>>> heapq.heappush(li, 3), li
(None, [1, 2, 4, 3])
>>> heapq.heappop(li), li
(1, [2, 3, 4])
>>> heapq.heappushpop(li, 5), li
(2, [3, 5, 4])
集合(set)
集合(set)是一个无序的不重复元素序列。
可以使用大括号 {1, 2, 3} 或者 set([1, 2, 3])(接收单个 iterable 参数)函数创建集合,
但是注意创建一个空集合必须用 set() 而不是 {},因为 {} 是用来创建一个空字典的。
下面约定
s与z都是集合,而e是集合中的元素(意味着它是可哈希的)。
集合的常用方法包括:
s.add(e)将元素e添加到集合s中;如果元素已存在,则不进行任何操作s.discard(e)将元素e从集合s中移除;如果元素不存在,则不进行任何操作s.pop()随机弹出集合中的一个元素;如果集合为空,抛出KeyError异常s.clear()移除掉s中的所有元素
支持的“集合论”操作有:
s & z创建并返回一个新集合,它是s和z的交集s | z创建并返回一个新集合,它是s和z的并集s - z创建并返回一个新集合,它是s和z的差集s ^ z创建并返回一个新集合,它是s和z的对称差集s &= z把s更新为s和z的交集s |= z把s更新为s和z的并集s -= z把s更新为s和z的差集s ^= z把s更新为s和z的对称差集
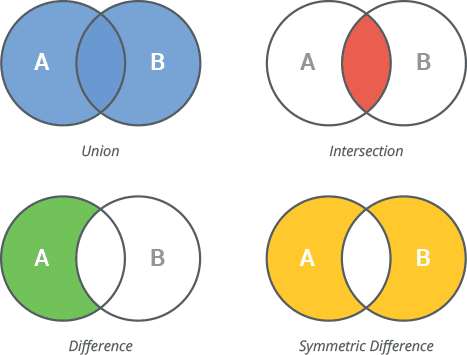
以及:
e in s测试元素e是否属于ss <= z测试s是否为z的子集s < z测试s是否为z的真子集s >= z与s > z同理
字典(dict)
字典就是哈希表,其键必须是可哈希的。
其常用方法有:
d.clear()移除所有元素d.get(k, [default])返回键k对应的值;如果没有键k,返回None或者defaultd.pop(k, [default])返回键k对应的值,然后移除这个键值对;如果没有键k,返回None或者default
另外有三个 O(1) 时间与空间复杂度的查询方法:
d.items()返回所有键值对(每个键值对以元组表示)的视图d.keys()返回所有键的视图d.values()返回所有值的视图
注意,视图意味着它们会随着 d 变化而变化。如果你需要快照,可以利用 iterable 的视图创建 list 等。
字典是以键为元素的 iterable,在遍历的时候要尤其注意。
>>> d = {'a': 1, 'b': 2}
>>> [k for k in d]
['a', 'b']
>>> [(k, v) for k, v in d.items()]
[('a', 1), ('b', 2)]
对于常见的“更新某个可能不存在的键”问题,你可以有两种写法:
# word count
cnt = {}
s = "abbacb"
for c in s:
if c not in cnt:
cnt[c] = 0
cnt[c] += 1
print(cnt)
# word count
cnt = {}
s = "abbacb"
for c in s:
cnt[c] = cnt.get(c, 0) + 1
print(cnt)
如果你喜欢我的文章,请我吃根冰棒吧 (o゜▽゜)o ☆

最后附上 GitHub:https://github.com/gonearewe