缓存系统可以加速数据操作。但它毕竟只是中间层, 数据的持久化与强一致性等还得依靠数据库。那么, 系统中的数据便分散在了两处,缓存与数据库间便出现了一致性问题。
只读数据不会出问题。而数据的并发读写、写写则会带来麻烦。 缓存系统与数据库各自都有措施来保证自身操作的原子性, 但两者的组合却不是原子的。 我们当然可以考虑引入分布式锁来保证组合操作的原子性, 但这也会影响系统吞吐量,这不是今天讨论的重点。 我们今天将考虑如何在不保证组合操作的原子性时维护一致性。
我们在使用缓存时通常会遵守三种经典的缓存模式之一,它们是:
Cache asideRead through / Write throughWrite behind
Cache aside
Cache aside 是较常用的模式,其读写流程如下:
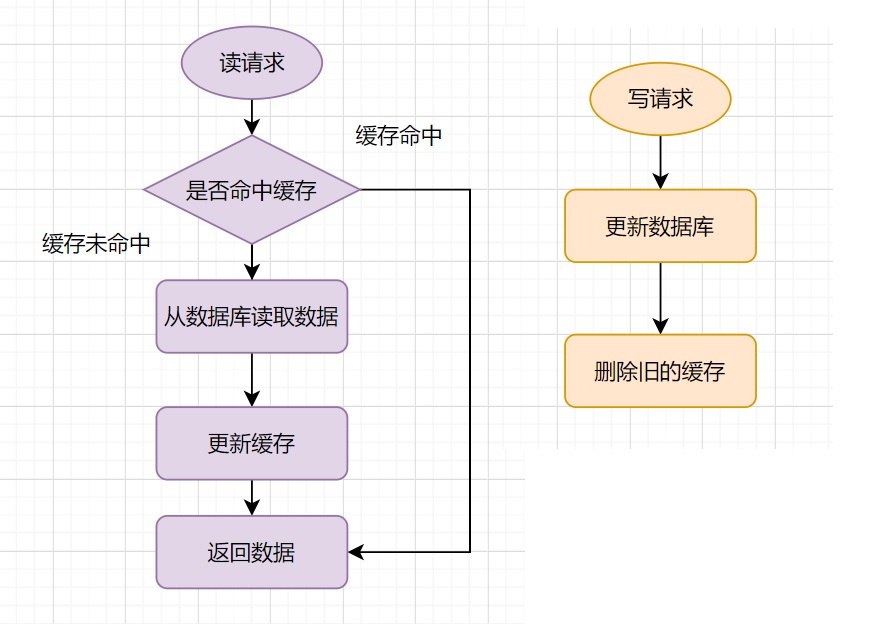
读流程没啥好说的。写流程中有两点值得注意。
其一,写流程中缓存一律删除(del)而不是更新(set)。
一个原因是程序未必知道数据库更新后的结果,
也就不清楚缓存应该更新成什么。
(比如 SQL 是 UPDATE table SET cnt=cnt+1 WHERE id=1 而非
UPDATE table SET cnt=100 WHERE id=1 这种简单 SQL,
鬼知道更新完数据是多少)不如直接删除,反正下次 Cache Miss 时会查询数据库添加最新缓存。另一个原因是“更新”策略可能会导致“写丢失”这种一致性问题。
例如,并发写的操作按这种顺序执行时:线程 A 更新数据库、
线程 B 更新数据库、线程 B 更新缓存、线程 B 更新缓存,
数据库中最终保存的是线程 B 的版本,但是缓存中 B 的数据却被 A 反过来覆盖了。
其二,先写数据库再写缓存而不是反过来。 假如反过来的话,考虑以下操作:
- 线程 A 发起一个写操作,第一步删缓存
- 线程 B 发起一个读操作,
Cache Miss,读出 DB 中的老数据,添加进缓存 - 线程 A 写入 DB 最新的数据
这下,缓存中的数据还是老的。
即使先写数据库再写缓存,也还要考虑数据库写成功,缓存删除失败的情况。 此时为了保证删除缓存成功,可以引入删除缓存重试机制。 但是也不能让应用同步阻塞在那里重试呐,最好由其他程序来进行重试, 比如,把删除失败的 key 放到消息队列中去,由队列接收者负责重试直到成功。
Read through / Write through
可以看到,数据使用者同时操作缓存与数据库还是十分复杂易错的; 而且这样设计使得数据使用者与数据层耦合在了一起, 如果有多个数据使用者,那它们需要遵守同一套操作规范。 因而,在大规模应用缓存的系统中,通常会构建一个数据范围的模块, 屏蔽缓存与数据库的操作细节。
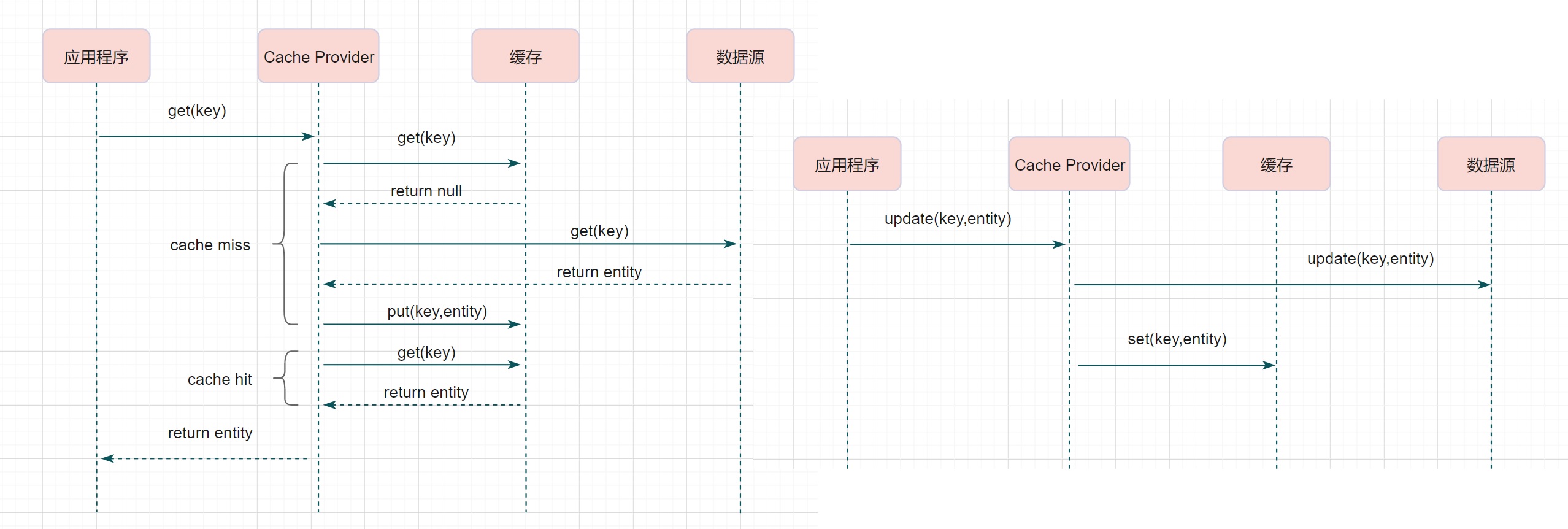
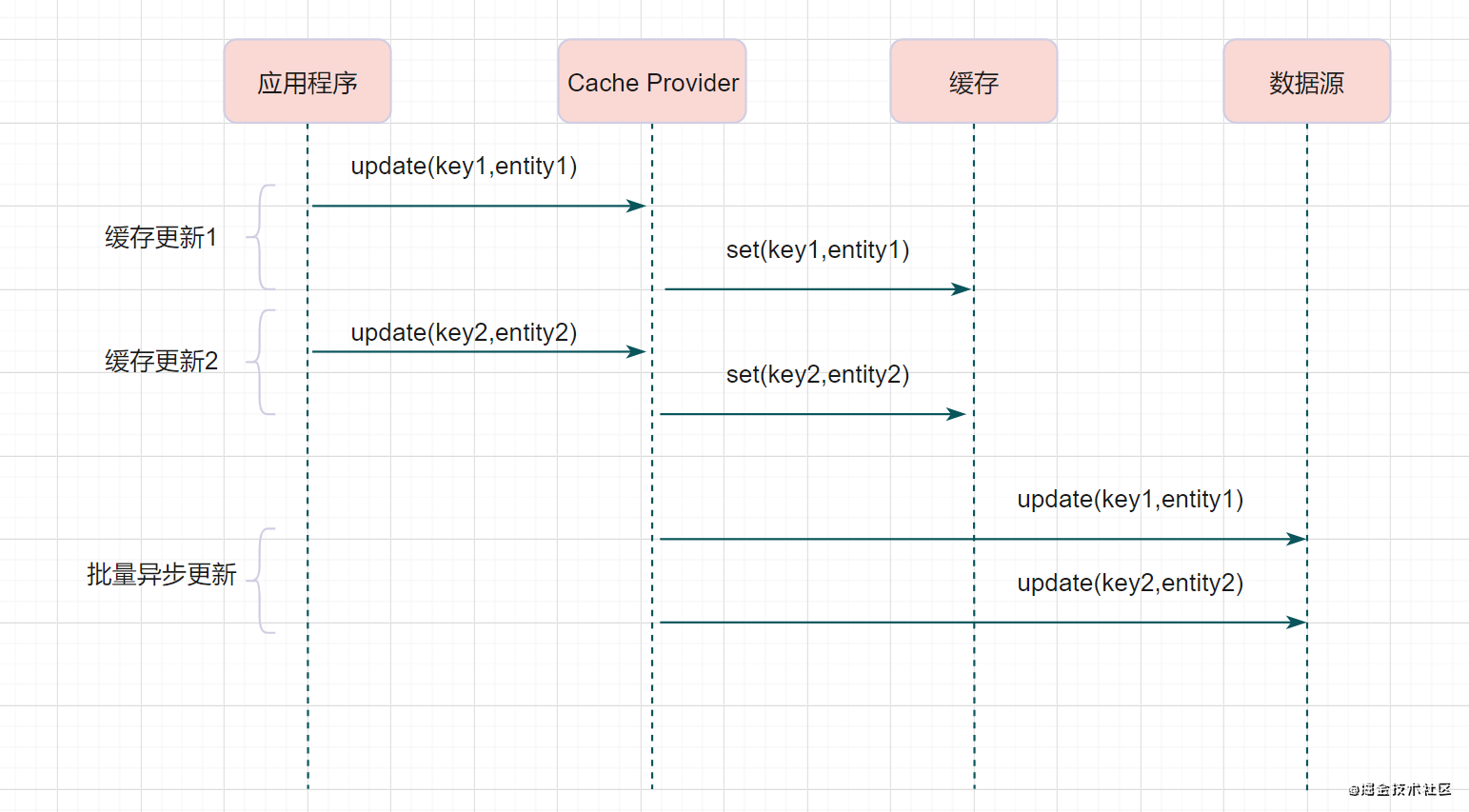
Write behind
Write behind 与前者很相似,都是由 Cache Provider 来负责缓存和数据库的读写。主要区别在于:Read through / Write through 是同步更新缓存和数据库的,而 Write behind 则是只更新缓存就返回,通过批量异步的方式来更新数据库。
参考资料:
如果你喜欢我的文章,请我吃根冰棒吧 (o゜▽゜)o ☆

最后附上 GitHub:https://github.com/gonearewe