系列上一篇文章中提到了 AQS 的队列部分基于 CLH Lock 的变种实现,但是原文并未详细介绍 CLH Lock,
所以本篇文章介绍一下原始的 CLH 锁以作补充。但是本篇文章的内容不止于此,如标题所示,我们将整体地讨论自旋锁,
看看 CLH 锁是如何一步一步的被引入的。
缓存一致性协议
当前主流的多核处理器均采用了共享内存:不同的核心共享相同的内存资源。然而由于访问内存耗时较长,共享内存不是直接将多核处理器连接到同一个物理内存,而是添加了多级高速缓存(Multilevel Cache)来缓存高频访问的数据。访问该缓存的速度远高于访问内存的速度,因此使用该缓存可以降低访问内存的概率从而减少访存开销。但是由于不同核心均拥有私有的高速缓存(如 L1 缓存),内存上某一地址的数据可能同时存在于多个核心的私有缓存中。
当任一核心修改该地址数据时,会导致不同核心上私有缓存中该地址数据的不一致,违反了共享内存的抽象。为了保证私有缓存之间也能就某一地址的值达成共识,多核硬件提供了缓存一致性协议(Cache Coherence Protocol)。
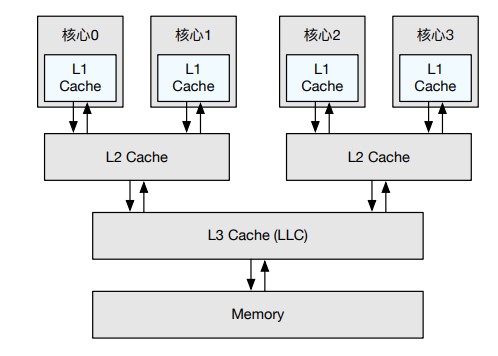
MESI 协议用于解决缓存一致性问题,它的名字来自它对 CPU 私有缓存行(cache line)的状态的标记:
Modified(修改):缓存行中的数据已经被修改,需要最终写回到主存中去,其他CPU也不能缓存该数据;Exclusive(独占):和Modified状态类似,区别是CPU没有修改数据;Shared(共享):缓存行中的数据被多个CPU共享,此时不能直接修改缓存行中的数据,而要先通知其他CPU;Invalid(无效):缓存行中的数据无效,相当于cache miss,缓存淘汰的时候也会优先置换该行。
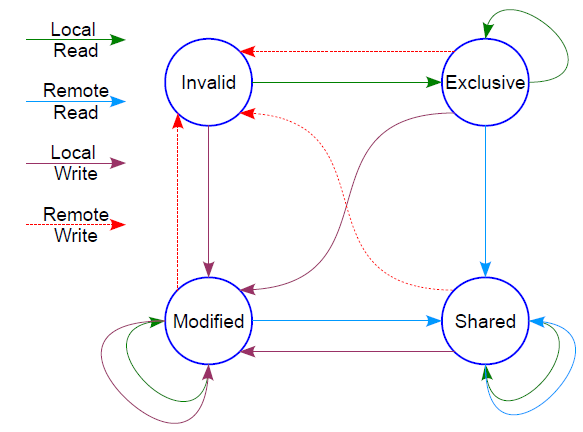
实际的实现还是比较复杂的,但是我们可以举一例以体会其思想。如果一个缓存行标记为 Shared,那么说明该数据有效且有多个 CPU 在共享它,
此时当前 CPU 可以安全地读它;当前 CPU 要写它(Local Write)时,会通知其他 CPU (其他 CPU 收到 Remote Write 信号)将该数据在各自的缓存行中的标记由 Shared 变为 Invalid,
同时将当前 CPU 的缓存行标记变为 Modified;在 Modified 标记下的数据是由自己独占的,可以自由读写;此时如果收到了 Remote Write 信号,
说明有其他 CPU 希望写该数据,那么给它最新值后把自己的缓存行置为 Invalid。
注意到,读写本地的缓存是很高效的,而缓存同步通常则需要占用总线通知其他 CPU 进行状态转移,开销相对较大。
TAS, TTAS and Back-Off
我们在系列的第一篇文章中就简要介绍了自旋 CAS 锁,当时只假设有两个线程在竞争一个锁,那么当有许多线程激烈竞争一个锁的时候又会如何呢。
我们这里引入一个新的用于同步的 CPU 原子指令 Test-and-Set,它返回某地址的旧值并设置其为给定的新值。用 JUC 的原子工具类表示如下:
public class TASLock {
private AtomicBoolean state = new AtomicBoolean(false);
public void lock() {
while (state.getAndSet(true)) {
// 自旋
}
}
public void unlock() {
state.set(false);
}
}
我们还知道多线程通常会被调度到多个 CPU 上执行。那么我们就会发现,每一个 CPU 进行各自的 TAS 时都会修改数据,
导致大量时间消耗在缓存一致性协议上,进而使得互斥锁无法快速有效地在不同的核心之间传递。因此我们引入了 Test-Test-and-Set 锁。
public class TTASLock {
private AtomicBoolean state = new AtomicBoolean(false);
public void lock() {
while (state.get() || state.getAndSet(true)) {
// 自旋
}
}
public void unlock() {
state.set(false);
}
}
假设有两个线程 a 与 b。a 先将 state 设为 true 以获得锁,其后 b 读取的 state 为 true(a 设置的),因而自旋在 state.get() 上,
在 a 释放锁后,b 才开始通过 TAS 争夺锁。因为每个线程在 state.get() 和 state.getAndSet(true) 两处 Test 锁,
所以称其为 Test-Test-and-Set 锁。它的改进在于争夺锁时,第一次的 state.get() 只是读取 state 而不尝试修改,
因而线程会自旋在私有缓存中的 state 上,不会像 TAS 锁一样持续触发缓存一致性协议的同步。
详细可参考 Dynamic Decentralized Cache Schemes for MIMD Parallel Processors
但是 TTAS 还是不够理想,性能问题主要出现在解锁上。一旦一个已经获得锁的线程执行解锁操作,修改 state,就依然会触发缓存同步,
其他线程都会结束本地自旋并尝试获取最新值,导致总线竞争变得骤然激烈。即,解锁的开销依然不小。这里引入一个直观的、无需大量修改的新策略:回退策略(Back-Off)。
public class TTASLock {
private AtomicBoolean state = new AtomicBoolean(false);
public void lock() {
while (state.get() || state.getAndSet(true)) {
delay();
}
}
public void unlock() {
state.set(false);
}
}
当竞争者拿不到锁时,它就不再继续尝试修改该缓存行,而是选择等一段时间再去拿锁。为了避免多个竞争者的等待时间相同,
回退策略可以为竞争者设定不同的等待时间,比如等待随机时长或依照一定序列依次加长等待时间(如指数增加等待时间)。
在处理器核心数较少时,回退锁因其等待策略的原因,性能弱于普通自旋锁。但当有更多核心时,其性能超过普通自旋锁,且随着核心数增加,
回退锁的吞吐率十分稳定,不再出现可扩展性断崖。其本质是通过等待,错开各 CPU 的 state 变量的同步更新时机以避免总线风暴。
注意这里的 delay() 绝不是 Thread.sleep() 这种阻塞挂起的系统调用,它的开销可比我们这里讨论的机器指令级别的开销大得多;
delay() 可以是计数等无意义但开销可控的操作,而且依然是在 CPU 上忙等浪费时间片。
详细可参考 The performance of spin lock alternatives for shared-money multiprocessors
回退策略对回退锁的性能影响较大,而且最优策略依赖于具体的平台、使用场景等,所以移植性不佳。后来也出现了一些自适应的回退锁, 可以动态调整回退策略。但是回退锁并没有解决本质问题,只是一定程度上减少了问题的出现。良好的可扩展互斥锁需要保证其竞争开销(如缓 存行失效的次数)不应随着竞争者数量增多而加大。因而下面引入队列锁。
Queue Lock
队列锁的具体实现不止一种,但思想大体一致,我们这里只介绍 CLH 锁,它以设计者们的名字首字母命名:Craig, Landin 和 Hagersten。
详细可参考 Queue Locks on Cache Coherent Multiprocessors 、Building FIFO and Priority-Queuing Spin Locks from Atomic Swap
CLH 锁能确保无饥饿性,提供先来先服务的公平性。它的巧妙点在于所有等待获取锁的线程的节点轻松且正确地构建成了全局队列,等待中的线程按队列依次获取锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。用 Java 模拟其实现如下:
public class CLHLock {
private static class Node {
volatile boolean locked;
}
private final AtomicReference<Node> tail;
private final ThreadLocal<Node> myPred;
private final ThreadLocal<Node> myNode;
public CLHLock() {
this.tail = new AtomicReference<>(new Node());
this.myNode = ThreadLocal.withInitial(Node::new);
this.myPred = new ThreadLocal<>();
}
public void lock() {
Node node = myNode.get();
node.locked = true;
Node pred = tail.getAndSet(node);
myPred.set(pred);
while (pred.locked);
}
public void unlock() {
Node node = myNode.get();
node.locked = false;
myNode.set(myPred.get());
}
}
竞争锁的线程把自己包装成 Node,myNode 和 myPred 使用 ThreadLocal 保存,与线程关联。
初始状态的 tail 的值是一个新的 Node,locked 的值是默认的 false,因而第一个加入的 Node 可以成功获取锁。
特别注意 unlock 中的
myNode.set(myPred.get());
它有以下几点影响:
- 将当前
node指向前驱node,lock方法中再也拿不到当前node的引用了。这样操作等于把当前node从链表头部删除(并不是被JVM回收,第二个线程的myPred还引用它) - 当前线程若要在
unlock之后再次拿锁需重新排队(每个线程自己都维护了两个Node,一个在释放锁的时候把当前node置为前驱node,另一个在lock方法的时候重新获取尾node作为前驱node) - 如果所有的任务都是由固定数量的线程池执行的话,你会看到所有的
Node的使用会形成一个环形链表(实际不是)。
另外为什么要有 myPred 字段,可不可以改成本地变量?
也就是代码改成这样:
public void lock() {
Node node = myNode.get();
node.locked = true;
Node pred = tail.getAndSet(node);
while (pred.locked);
}
public void unlock() {
Node node = myNode.get();
node.locked = false;
}
答案是不行。
假设有两个线程:T1 与 T2,T1 持有锁,T2 等待 T1 释放锁。
这时候 T1.node.locked 为 true,T2.node.locked 也为 true,tail 变量指向 T2.node,但 T2 正在 pred.locked 自旋。
这里的 pred 也就是 T1.node。
现在 T1 开始释放锁(设置 T1.node.locked 为 false)并且在 T2 抢占到锁之前再次获取锁,此时 T1.node.locked 再次变成 true,
但是此时的尾节点是 T2.node,所以 T1 只好等待 T2 释放锁。而 T2 也在等待 T1 释放锁,死锁发生了。
再结合上面 myNode.set(myPred.get()) 代码的解释,myPred 字段提供了两点好处:
- 防止死锁发生,释放锁的时候也就释放了当前节点的引用
- 等待队列中节点具有顺序性(看日志打印)可保证锁竞争公平,每个等待锁的线程都持有前驱节点的引用(
getAndSet返回),n个线程最后有n+1个节点(有一个是初始tail的node),所有的节点按照顺序循环使用。借助于myPred在释放锁后若要再次拿锁需排队且排在最后。
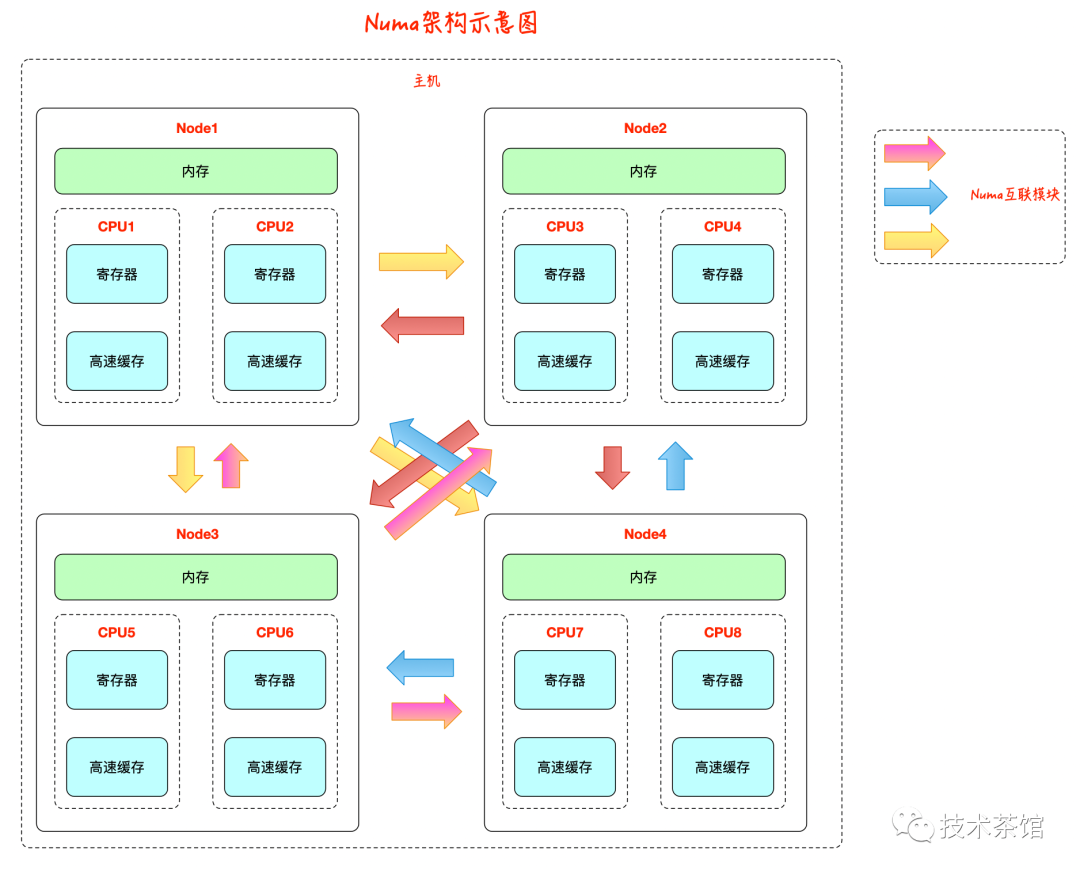
CLH 的缺点在于在 NUMA 系统结构下性能很差,在这种系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,
自旋判断前趋结点的 locked 域,性能将大打折扣,但是在 SMP 系统结构下该法还是非常有效的。一种针对 NUMA 系统结构优化的队列锁是 MCS 锁。
它是由 John M. Mellor-Crummey 与 Michael L. Scott 在 1991 年提出的,MCS 锁也因此得名(MC 与 S 分别为两位作者姓氏首字母)。
但是这里不再介绍,MCS 的设计可参考原论文 Algorithms for Scalable Synchronization on
SharedMemory Multiprocessor。
SMP(Symmetric Multi-Processor),即对称多处理器结构,指处理器中多个CPU对称工作,每个CPU访问内存地址所需时间相同。 其主要特征是共享,包含对CPU,内存,I/O等进行共享。SMP的优点是能够保证内存一致性,缺点是这些共享的资源很可能成为性能瓶颈, 随着CPU数量的增加,每个CPU都要访问相同的内存资源,可能导致内存访问冲突,可能会导致CPU资源的浪费。常用的PC机就属于这种。
NUMA(Non-Uniform Memory Access),即非一致存储访问,将处理器分为多个CPU模块,每个CPU模块由多个CPU组成, 并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存) 的速度,这也是非一致存储访问NUMA的由来。NUMA优点是可以较好地解决原来SMP系统的扩展问题, 缺点是由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
总结
我们自缓存一致性协议的基础开始,从锁竞争的性能角度出发,依此讨论了 TAS, TTAS, Back-Off 与 Queue Lock。
TTAS 相对基本的原子锁 TAS 降低了锁竞争时的开销,但是锁释放的开销不变。Back-Off Lock 试图通过回退策略解决这一问题,
但是回退策略的具体实现影响了移植性。Queue Lock 通过更复杂的实现将锁竞争的开销均摊到队列节点的操作上去。这些基本上
就是自旋锁的所有实现了,它们基本上都有应用。后来还有针对它们的自适应算法,比如根据实际情况动态切换自旋锁算法的算法,
可以参考 Reactive Spin-locks: A Self-tuning Approach。了解这些自旋锁对于深入理解高层次的并发框架的实现大有裨益。
参考资料:
如果你喜欢我的文章,请我吃根冰棒吧 (o゜▽゜)o ☆

最后附上 GitHub:<https://github.com/gonearew