这是我很久前做的一个项目(commit 记录显示时间是 2019.10-2020.1),根据张秀宏前辈的《自己动手实现 Lua:虚拟机、编译器和标准库》
用 Go 实现的。因为代码量不小,很多函数书上都只有功能描述,具体实现都是自己独立完成的。项目做完体会还是很深的,但是
当时还没有记录项目体会的习惯。现在为了暑假实习,把它写上简历了,特地回来回顾一下。为减轻文章编写压力,下面很多的内容都摘自原文。
我的项目在 Github 开源,原书随书代码亦开源
书籍则可在各大电商平台购买。
虚拟机
加载 chunk
Lua 是一门以高效著称的脚本语言,从 1.0 版(1993年发布)开始就内置了虚拟机。也就是说,Lua 脚本并不是直接被 Lua 解释器解释执行,
而是类似 Java 语言那样,先由 Lua 编译器编译为字节码,然后再交给 Lua 虚拟机去执行。
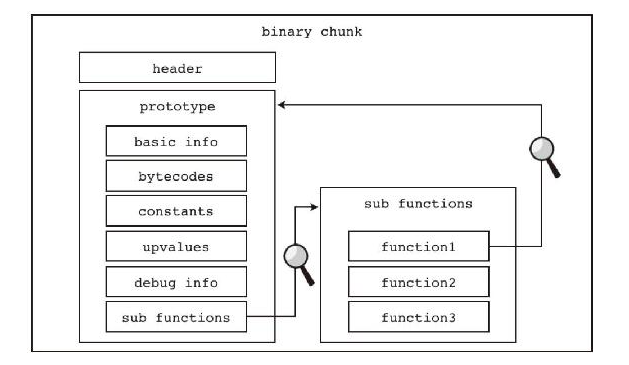
Lua 字节码需要一个载体,这个载体就是二进制 chunk,类似于 Java 的 class 文件。
Lua 编译器以函数为单位进行编译,每一个函数都会被 Lua 编译器编译为一个内部结构,这个结构叫作“原型”(Prototype)。
原型主要包含 6 部分内容,分别是:函数基本信息(包括参数数量、局部变量数量等)、字节码、常量表、Upvalue 表、调式信息、子函数原型列表。
由此可知,函数原型是一种递归结构,并且 Lua 源码中函数的嵌套关系会直接反映在编译后的原型里。
同许多二进制文件一样,chunk 包含文件头,头部含有签名、版本号、格式号、各种整数类型占用的字节数,以及大小端和浮点数格式识别信息等。
我们下面先定义好 chunk 的数据结构。
type binaryChunk struct {
header
sizeUpvalues byte
mainFunc *Prototype
}
type header struct {
signature [4]byte // magic number 0x1B4C7561, for identifying chunk file
version byte // for version x.y.z, it is x*16+y
format byte // default value is 0
luacData [6]byte // for verifying file, "\x19\x93\r\n\x1a\n"
cintSize byte
sizetSize byte
instructionSize byte
luaIntegerSize byte
luaNumberSize byte
luacInt int64 // stores 0x5678, used to determine Big-endian or Little-endian
luacNum float32 // stores 370.5, used to determine number format(usually IEEE 754)
}
type Prototype struct {
Source string // where source comes form, only not empty in main function
LineDefined uint32 // where this prototype starts in source file(line index), main function always starts with 0
LastLineDefined uint32 // where this prototype ends in source file(line index)
NumParams byte // useless if IsVararg is 1(true)
IsVararg byte // whether this prototype accepts parametres of variable numbers, 0 for false and 1 for true
MaxStackSize byte // how many virtual registers this function needs at least, stack is used to virtualize register
Code []uint32 // list of instructions
Constants []interface{}
Upvalues []Upvalue
Protos []*Prototype // list of sub-functions
LineInfo []uint32 // list of line indexes, mapped to Code(the instruction list)
LocVars []LocVar // list of local variables
UpvalueNames []string // mapped to Upvalues
}
然后我们需要一个 reader 来把二进制字节流转换为上面的 chunk 数据结构。
type reader struct {
data []byte
}
// param parentSource indicates where the source of the chunk file comes from
// chunk file only save this information for main function,
// thus it requires to be passed to every subfunctions
// read sub-functions recursively
func (r *reader) readProtos(parentSource string) []*Prototype {
protos := make([]*Prototype, r.readUint32())
for i := range protos {
protos[i] = r.readProto(parentSource)
}
return protos
}
func (r *reader) readLocVars() []LocVar {
locVars := make([]LocVar, r.readUint32())
for i := range locVars {
locVars[i] = LocVar{
VarName: r.readString(),
StartPC: r.readUint32(),
EndPC: r.readUint32(),
}
}
return locVars
}
// ... more functions
至此,第一步就做好了。
虚拟机动态结构
Lua State
虚拟机的核心就是 Lua State,其内部封装的最为基础的一个状态就是虚拟栈(后面我们称其为 Lua 栈)。
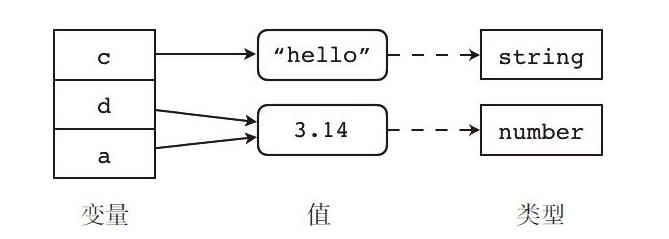
Lua 是动态类型语言,在 Lua 代码里,变量是不携带类型信息的,变量的值才携带类型信息。
换句话说,任何一个 Lua 变量都可以被赋予任意类型的值。(类似 Python)
local a, b, c
c = false -- boolean
c = {1, 2, 3} -- table
c = "hello" -- string
a = 3.14 -- number
b = a
Lua 一共支持 8 种数据类型,分别是 nil、布尔(boolean)、数字(number)、字符串(string)、表(table)、函数(function)、线程(thread)和用户数据(userdata)。它们很容易用 Go 的原生类型实现。
针对 Lua State 进行操作的一组函数称为 Lua API。这些函数大致可以分为基础栈操纵方法、栈访问方法、压栈方法三类。
我们可以用接口(interface)来描述 LuaState。
type LuaState interface {
/* basic stack manipulation */
GetTop() int
AbsIndex(idx int) int
CheckStack(n int) bool
Pop(n int)
Copy(fromIdx, toIdx int)
PushValue(idx int)
Insert(idx int)
// ...
/* access functions (stack -> Go) */
TypeName(tp LuaType) string
Type(idx int) LuaType
IsNone(idx int) bool
IsNil(idx int) bool
IsNoneOrNil(idx int) bool
IsBoolean(idx int) bool
IsInteger(idx int) bool
IsNumber(idx int) bool
IsString(idx int) bool
ToBoolean(idx int) bool
ToInteger(idx int) int64
ToNumber(idx int) float64
ToString(idx int) string
// ...
/* push functions (Go -> stack) */
PushNil()
PushBoolean(b bool)
PushInteger(n int64)
PushNumber(n float64)
PushString(s string)
}
然后我们为其提供“实现类” luaState,因为 Go 采用鸭子接口(duck type),所以我们不需要显式声明“实现”(implements)关系。
type luaState struct {
stack *luaStack
}
func New() *luaState {
// ...
}
// ... more functions
luaState 内嵌 luaStack 来实现基本的栈操作。Lua 虚拟机不同于 JVM 这种栈式虚拟机,它是寄存器式虚拟机,
这意味着它额外支持按索引操作(读、写、插入等)栈内元素。
栈式虚拟机相对来说实现简单、传输代码较小
寄存器式虚拟机相对来说表示同样程序逻辑的指令条数较少,纯解释执行的速度较快
type luaStack struct {
slots []luaValue
top int // index of the top of the lua stack, notice that index starts with 1
pc int
state *luaState
}
func (l *luaStack) push(val luaValue) {
// ...
}
func (l *luaStack) pop() luaValue {
// ...
}
// Get value from the stack by relevant index,
// returns the registry if idx is fake index of registry
// returns nil if the index is invalid.
func (l *luaStack) get(idx int) luaValue {
// ...
}
func (l *luaStack) set(idx int, val luaValue) {
// ...
}
LuaVM
因为 Lua State 是 LuaVM 的主体,我们直接让 LuaVM 接口内嵌 LuaState。
type LuaVM interface {
LuaState
PC() int // 返回当前PC(仅测试用)
AddPC(n int) // 修改PC(用于实现跳转指令)
Fetch() uint32 // 取出当前指令;将PC指向下一条指令
GetConst(idx int) // 将指定常量推入栈顶
}
LuaVM 还增加了 5 个方法。其中 AddPC() 用于修改当前 PC,这个方法是实现跳转指令所必需的;
Fetch() 用于取出当前指令,同时递增 PC,让其指向下一条指令,这个方法主要是虚拟机循环会用;
GetConst() 用于从常量表里取出指定常量并推入栈顶;
PC() 用于返回当前 PC,这个方法也不是必需的,我们仅在测试中使用它。
我们直接扩展 LuaState 的“实现类” luaState 使其同时实现 LuaVM 接口,我们为接口实现方法。
type luaState struct {
stack *luaStack
// 下面是新添加的字段
proto *binchunk.Prototype
pc int
}
func (self *luaState) PC() int {
return self.pc
}
func (self *luaState) AddPC(n int) {
self.pc += n
}
func (self *luaState) Fetch() uint32 {
i := self.proto.Code[self.pc]
self.pc++
return i
}
func (self *luaState) GetConst(idx int) {
c := self.proto.Constants[idx]
self.stack.push(c)
}
指令执行
实际上虚拟机工作时通常进行这样的大循环:根据 PC 从代码段取指令、PC 自增、执行指令操作数据。
那么我们就必须用 Lua API 来实现虚拟机的指令。例如:
func move(i Instruction, vm LuaVM) {
a, b, _ := i.ABC()
a += 1; b += 1
vm.Copy(b, a)
}
func jmp(i Instruction, vm LuaVM) {
a, sBx := i.AsBx()
vm.AddPC(sBx)
if a != 0 {
panic("todo!")
}
}
实际上,虚拟机的指令数量非常之多(包括控制转移指令、算术运算指令、逻辑运算指令等),我当初在这里花费了相当多的时间。
我们可以使用一个大大的 switch-case 语句来进行指令分派(Dispatch)。
但是因为 Go 支持一等函数(First-class Function),所以我们可以转而采用表驱动的方式。(可惜 Go 不支持 pattern match)
如果在一门编程语言里,函数属于一等公民(First-class Citizen),我们就说这门语言里的函数是一等函数(First-class Function)。 其实就是说函数用起来和其他类型的值(比如数字或者字符串)没什么分别,比如说可以把函数存储在数据结构里、赋值给变量、作为参数传递给其他函数或者作为返回值从其他函数里返回等。
type opcode struct {
// ...
action func(i Instruction, vm api.LuaVM)
}
var opcodes = []opcode{
/* T A B C mode name action */
opcode{0, 1, OpArgR, OpArgN, IABC, "MOVE ", move },
opcode{0, 1, OpArgK, OpArgN, IABx, "LOADK ", loadK },
opcode{0, 1, OpArgN, OpArgN, IABx, "LOADKX ", loadKx },
opcode{0, 1, OpArgU, OpArgU, IABC, "LOADBOOL", loadBool},
opcode{0, 1, OpArgU, OpArgN, IABC, "LOADNIL ", loadNil },
// ...
}
type Instruction uint32
func (self Instruction) Execute(vm api.LuaVM) {
action := opcodes[self.Opcode()].action
if action != nil {
action(self, vm)
} else {
panic(self.OpName())
}
}
至此,我们的虚拟机就像一个计算器一样了,它可以执行简单的语句。
函数调用
函数(或者子程序、方法)的定义和调用是任何编程语言都必须具备的能力,我们下一步就是实现函数调用。
函数调用也经常借助“栈”这种数据结构来实现。为了区别于 Lua 栈,我们称其为函数调用栈,简称调用栈(Call Stack)。
Lua 栈里面存放的是 Lua 值,调用栈里存放的则是调用栈帧,简称为调用帧(Call Frame)。
我们直接扩展 luaStack,使它成为调用帧。
type luaStack struct {
slots []luaValue
top int // index of the top of the lua stack, notice that index starts with 1
prev *luaStack // use linked list to achieve function call-back stack
varargs []luaValue
pc int
state *luaState
}
新增的字段 prev 暗示 luaStack 成了单链表的结点,这个单链表就是函数调用栈。
varargs 表示当前调用帧对应的函数的可变输入参数。
我们接着让 luaState 实现 push 和 pop 调用帧的方法,如此一来 luaState 就控制了函数调用栈。
type luaState struct {
stack *luaStack
proto *binchunk.Prototype
pc int
}
func New() *luaState {
// ...
}
// Add a head node to the linked list.
func (l *luaState) pushLuaStack(stack *luaStack) {
stack.prev = l.stack
l.stack = stack
}
// Delete the head node of the linked list.
func (l *luaState) popLuaStack() {
stack := l.stack
l.stack = stack.prev
stack.prev = nil
}
// ... more functions
至此,虚拟机的部分就算完成了。
编译器
主要的编译阶段分为前端(Front End)、中端(Middle End)和后端(Back End),
其中前端包括预处理、词法分析、语法分析、语义分析和中间代码生成;中端主要进行中间代码优化;后端则进行目标代码生成。
Lua 不像 C 那样支持宏等特性,不需要进行预处理;语义分析最重要的一项工作是类型检查,而由于 Lua 是动态类型语言,
在编译期不需要进行类型检查,所以我们也不讨论语义分析阶段;出于减少工作量的考虑,中间语言生成和优化阶段也跳过。
最终我们仅进行词法分析、语法分析和代码生成这三个阶段。
词法分析器
源代码通常以字符流形式给出,这并不方便后续的处理。因而我们首先需要把源代码(字符流)分解为 token 流。
token 按其作用可以分为不同的类型,比较常见的类型注释、关键字、标识符、字面量、运算符、分隔符等。
我们定义一个词法分析器(Lexer)来完成这项工作。
词法分析器一般使用有限状态机(Finite-state Machine,FSM)实现,有关有限状态机的知识可以自行 Google。
type Lexer struct {
chunk string // 源代码
chunkName string // 源文件名
line int // 当前行号
}
func (self *Lexer) NextToken() (line, kind int, token string) {
self.skipWhiteSpaces()
if len(self.chunk) == 0 {
return self.line, TOKEN_EOF, "EOF"
}
switch self.chunk[0] {
case ';': self.next(1); return self.line, TOKEN_SEP_SEMI, ""
case ',': self.next(1); return self.line, TOKEN_SEP_COMMA, ""
// ...
case '=':
if self.test("==") {
self.next(2); return self.line, TOKEN_OP_EQ, "=="
} else {
self.next(1); return self.line, TOKEN_OP_ASSIGN, "="
}
case '<':
if self.test("<<") {
self.next(2); return self.line, TOKEN_OP_SHL, "<<"
} else if self.test("<=") {
self.next(2); return self.line, TOKEN_OP_LE, "<="
} else {
self.next(1); return self.line, TOKEN_OP_LT, "<"
}
}
某些 token 有公共的前缀(如 “«”,”<=”,”<”),为了区分它们,我们只需要前瞻几个字符。
语法分析器
接下来的语法分析阶段,我们需要根据语法规则将 token 序列解析为抽象语法树(AST)。
在命令式编程语言里,语句(Statement)是最基本的执行单位,表达式(Expression)则是构成语句的要素之一。
语句和表达式的主要区别在于:语句只能执行不能用于求值,而表达式只能用于求值不能单独执行。
语句和表达式也并非泾渭分明,比如在 Lua 里,函数调用既可以是表达式,也可以是语句。
我们用扩展巴科斯范式(Extended Backus-Naur Form,EBNF)表示 Lua 语句如下:
stat ::= ';'
| varlist '=' explist
| functioncall
| label
| break
| goto Name
| do block end
| while exp do block end
| repeat block until exp
| if exp then block {elseif exp then block} [else block] end
| for Name '=' exp ',' exp [',' exp] do block end
| for namelist in explist do block end
| function funcname funcbody
| local function Name funcbody
| local namelist ['=' explist]
而 Lua 一共有 5 类表达式:字面量表达式、构造器表达式、运算符表达式、vararg 表达式和前缀表达式。
字面量表达式包括 nil、布尔、数字和字符串表达式。构造器表达式包括表构造器和函数构造器表达式。
运算符表达式包括一元和二元运算符表达式。下面是表达式的 EBNF 描述:
exp ::= nil | false | true | Numeral | LiteralString | '...'
| functiondef | prefixexp | tableconstructor
| exp binop exp | unop exp
我们可以把它们变成代码里的数据类型。
type Exp interface{}
type NilExp /* */ struct{ Line int }
type TrueExp /* */ struct{ Line int }
type FalseExp /* */ struct{ Line int }
type IntegerExp struct {
Line int
Val int64
}
type StringExp struct {
Line int
Str string
}
// exp1 op exp2
type BinopExp struct {
Line int // line of operator
Op int // operator
Exp1 Exp
Exp2 Exp
}
// EBNF:
// functiondef::=function funcbody
// funcbody::= '(' [parlist] ')' block end
// parlist::= namelist [',' '...'] | '...'
// namelist::= Name {',' Name}
type FuncDefExp struct {
Line int
LastLine int
ParList []string
IsVararg bool
Block *Block
}
// EBNF:
// functioncall::=prefixexp [':' Name] args
// args::= '(' [explist] ')' | tableconstructor | LiteralString
type FuncCallExp struct {
Line int // line of `(`
LastLine int // line of `)`
PrefixExp Exp
NameExp *StringExp
Args []Exp
}
// ... more expr
type Stat interface{}
type BreakStat /**/ struct{ Line int } // break
type DoStat /* */ struct{ Block *Block } // do block end
type FuncCallStat = FuncCallExp // function call, both statement and expression
// EBNF: while exp do block end
type WhileStat struct {
Exp Exp
Block *Block
}
// simplified EBNF: if exp then block {elseif exp then block} end
type IfStat struct {
// index 0 contains if-then, others contain elseif-then
Exps []Exp
Blocks []*Block
}
// EBNF:
// for namelist in explist do block end
// namelist::= Name {',' Name}
// explist::= exp {',' exp}
type ForInStat struct {
LineOfDo int
NameList []string
ExpList []Exp
Block *Block
}
// ... more stat
与前面的词法分析类似,我们同样利用有限状态机来构造 AST,不同的是,现在状态机接受的基本单元为 token 而非字符。
AST 构造方式主要有两种:自顶向下(Top-down)法与自底向上(Bottom-up)法。
自底向上的解析器包括 LR 解析器和 CYK 解析器等,自顶向下的解析器包括 LL 解析器和递归下降解析器(Recursive Descent Parser)等。
我们这里实现的是最简单的递归下降解析器。
func parseStat(lexer *Lexer) Stat {
switch lexer.LookAhead() {
case TOKEN_SEP_SEMI:
return parseEmptyStat(lexer)
case TOKEN_KW_BREAK:
return parseBreakStat(lexer)
case TOKEN_SEP_LABEL:
return parseLabelStat(lexer)
case TOKEN_KW_GOTO:
return parseGotoStat(lexer)
case TOKEN_KW_DO:
return parseDoStat(lexer)
case TOKEN_KW_WHILE:
return parseWhileStat(lexer)
case TOKEN_KW_REPEAT:
return parseRepeatStat(lexer)
case TOKEN_KW_IF:
return parseIfStat(lexer)
case TOKEN_KW_FOR:
return parseForStat(lexer)
case TOKEN_KW_FUNCTION:
return parseFuncDefStat(lexer)
case TOKEN_KW_LOCAL:
return parseLocalAssignOrFuncDefStat(lexer)
default:
return parseAssignOrFuncCallStat(lexer)
}
}
func parseBlock(lexer *Lexer) *Block {
return &Block{
Stats: parseStats(lexer),
RetExps: parseRetExps(lexer),
LastLine: lexer.Line(),
}
}
func parseStats(lexer *Lexer) []Stat {
stats := make([]Stat, 0, 8)
for !_isReturnOrBlockEnd(lexer.LookAhead()) {
stat := parseStat(lexer)
if _, ok := stat.(*EmptyStat); !ok {
stats = append(stats, stat)
}
}
return stats
}
// ... more parser methods
其中注意运算符表达式语法存在歧义,例如,如果我们这样定义逻辑表达式:
exp ::= exp (or | and) exp
那么 true and false or true 就可能被解析为:
and
/ \
true or
/ \
false true
或
or
/ \
and true
/ \
true false
为了消除歧义需要引入语义规则,那就是 Lua 运算符的优先级和结合性。
我们根据运算符优先级书写表达式的 EBNF 描述如下:
exp ::= exp12
exp12 ::= exp11 {or exp11}
exp11 ::= exp10 {and exp10}
exp10 ::= exp9 {('<' | '>' | '<=' | '>=' | '~=' | '==') exp9}
exp9 ::= exp8 {'|' exp8}
exp8 ::= exp7 {'~' exp7}
exp7 ::= exp6 {'&' exp6}
exp6 ::= exp5 {('<<' | '>>') exp5}
exp5 ::= exp4 {'..' exp4}
exp4 ::= exp3 {('+' | '-' | '*' | '/' | '//' | '%') exp3}
exp2 ::= {('not' | '#' | '-' | '~')} exp1
exp1 ::= exp0 {'^' exp2}
exp0 ::= nil | false | true | Numeral | LiteralString
| '...' | functiondef | prefixexp | tableconstructor
可以发现,exp 被层次化描述,如此一来,解析器读取 exp 时会递归地下探直到基本表达式 exp0(字面量等),
然后回溯完成表达式树的构建。
回到上面的例子,现在 true and false or true 只可能被解析为:
exp12 --> or
/ \
exp11 --> and true <-- exp0
/ \
exp0 --> true false <-- exp0
EBNF:
exp ::= exp12
exp12 ::= exp11 {or exp11}
exp11 ::= exp10 {and exp10}
因为 and 表达式的优先级比 or 表达式的优先级高。
我们依此实现:
func parseExp(lexer *Lexer) Exp {
return parseExp12(lexer)
}
// x or y
func parseExp12(lexer *Lexer) Exp {
exp := parseExp11(lexer)
for lexer.LookAhead() == TOKEN_OP_OR {
line, op, _ := lexer.NextToken()
lor := &BinopExp{line, op, exp, parseExp11(lexer)}
exp = optimizeLogicalOr(lor)
}
return exp
}
// x and y
func parseExp11(lexer *Lexer) Exp {
exp := parseExp10(lexer)
for lexer.LookAhead() == TOKEN_OP_AND {
line, op, _ := lexer.NextToken()
land := &BinopExp{line, op, exp, parseExp10(lexer)}
exp = optimizeLogicalAnd(land)
}
return exp
}
// ... more expr parser methods
代码生成器
我们进一步对上面得到的 AST 进行处理,利用它生成 Lua 字节码和函数原型,并最终输出二进制 chunk 文件。
我们一开始实现虚拟机时就定义了表示二进制 chunk 文件的数据类型,尤其是核心的 Prototype。
一个朴素的想法是,在这里直接利用它作为代码生成的结果。但是注意,那是一个纯粹的数据类型(data type),
即它不拥有方法,仅包含字段。而代码生成是一个动态的过程,我们还需要定义一个代码生成器。
因此,我们把代码生成分为两个阶段:第一个阶段对 AST 进行处理,逐渐生成自定义的内部结构;第二个阶段把内部结构转换为 Prototype。
type funcInfo struct {
insts []uint32 // corresponded instructions in binary chunk
constants map[interface{}]int // key is the constant's value and val is it's index in the constant list
usedRegs int
maxRegs int
scopeLv int
locVars []*locVarInfo // all declared local variables in order
locNames map[string]*locVarInfo // current valid relationship between variable's name and the actual variable
breaks [][]int // maintain addresses of `break` jmp
parent *funcInfo
upvalues map[string]upvalInfo
subFuncs []*funcInfo
numParams int
isVararg bool
}
当然还要有配套的转换函数:
func toProto(fi *funcInfo) *Prototype {
proto := &Prototype{
NumParams: byte(fi.numParams),
MaxStackSize: byte(fi.maxRegs),
Code: fi.insts,
Constants: getConstants(fi),
Upvalues: getUpvalues(fi),
Protos: toProtos(fi.subFuncs),
LineInfo: []uint32{},
LocVars: []LocVar{},
UpvalueNames: []string{},
}
if fi.isVararg {
proto.IsVararg = 1
}
return proto
}
// ...
funcInfo 主要要构造的有:常量表(存放函数体内出现的数字、字符串字面量等),
寄存器分配信息(已分配的寄存器数量和需要的最大寄存器数量)、局部变量表和代码段字节码等。
func (self *funcInfo) allocReg() int {
self.usedRegs++
if self.usedRegs >= 255 {
panic("function or expression needs too many registers")
}
if self.usedRegs > self.maxRegs {
self.maxRegs = self.usedRegs
}
return self.usedRegs - 1
}
func (self *funcInfo) freeReg() {
if self.usedRegs <= 0 {
panic("usedRegs <= 0 !")
}
self.usedRegs--
}
// ... more register methods
func (f *funcInfo) addLocVar(name string) int {
newVar := &locVarInfo{
name: name,
prev: f.locNames[name],
scopeLv: f.scopeLv,
slot: f.allocReg(),
}
f.locVars = append(f.locVars, newVar)
f.locNames[name] = newVar
return newVar.slot
}
// ... more local variable methods
// r[a] = r[b]
func (self *funcInfo) emitMove(a, b int) {
self.emitABC(OP_MOVE, a, b, 0)
}
// ... more instruction methods
我们对于 AST 的不同组成成分提供不同的代码生成函数。
func cgStat(fi *funcInfo, node Stat) {
switch stat := node.(type) {
case *FuncCallStat:
cgFuncCallStat(fi, stat)
case *BreakStat:
cgBreakStat(fi, stat)
case *DoStat:
cgDoStat(fi, stat)
case *WhileStat:
cgWhileStat(fi, stat)
case *RepeatStat:
cgRepeatStat(fi, stat)
case *IfStat:
cgIfStat(fi, stat)
case *ForNumStat:
cgForNumStat(fi, stat)
case *ForInStat:
cgForInStat(fi, stat)
case *AssignStat:
cgAssignStat(fi, stat)
case *LocalVarDeclStat:
cgLocalVarDeclStat(fi, stat)
case *LocalFuncDefStat:
cgLocalFuncDefStat(fi, stat)
case *LabelStat, *GotoStat:
panic("label and goto statements are not supported!")
}
}
这些代码生成函数知道如何分配与释放寄存器,如何根据作用域收集局部变量等。
func cgWhileStat(fi *funcInfo, node *WhileStat) {
pcBeforeExp := fi.pc()
r := fi.allocRegs()
cgExp(fi, node.Exp, r, 1)
fi.freeReg()
fi.emitTest(r, 0)
pcJmpToEnd := fi.emitJmp(0, 0)
fi.enterScope(true)
cgBlock(fi, node.Block)
fi.closeOpenUpvals()
fi.emitJmp(0, pcBeforeExp-fi.pc()-1)
fi.exitScope()
fi.fixSbx(pcJmpToEnd, fi.pc()-pcJmpToEnd)
}
// ...
代码生成器遍历完 AST 后,我们的 funcInfo 就构造完成了,之后便可先转换成 Prototype,再添加 header 封装为 chunk 写入文件。
如果你喜欢我的文章,请我吃根冰棒吧 (o゜▽゜)o ☆

最后附上 GitHub:https://github.com/gonearewe